
IntroToAssemblyArchANDAssembDebuggerHTB
Architecture
Assembly Language
我们与个人电脑和智能手机的大部分互动都是通过操作系统和其他应用程序完成的。这些应用程序通常使用高级语言开发,如C++,Java,Python等。我们还知道,这些设备中的每一个都有一个核心处理器,它运行所有必要的进程来执行系统和应用程序,沿着的还有随机存取存储器(RAM)、视频存储器和其他类似的组件。
然而,这些物理组件不能解释或理解高级语言,因为它们基本上只能处理1和0。这就是汇编语言的用武之地,作为一种低级语言,它可以编写处理器可以理解的直接指令。由于处理器只能处理二进制数据“即1和0”,因此人类在不参考手册的情况下与处理器交互以了解哪个十六进制代码运行哪个指令将是具有挑战性的。
这就是为什么低级汇编语言被建立起来的原因。通过使用汇编,开发人员可以编写人类可读的机器指令,然后将其汇编成等效的机器代码,以便处理器可以直接运行它们。这就是为什么有些人把汇编语言称为符号机器码的原因。例如,汇编代码’add rax, 1‘比其等效的机器外壳代码’4883C001‘更直观,更容易记住,并且比等效的二进制机器代码’01001000 10000011 11000000 00000001‘更容易记住。正如我们所看到的,没有汇编语言,编写机器指令或直接与处理器交互是非常具有挑战性的。
机器码通常表示为Shellcode,机器码字节的十六进制表示。Shellcode可以被翻译回它的汇编副本,也可以作为二进制指令直接加载到内存中执行。
High-level vs. Low-level
由于有不同的处理器设计,每个处理器理解不同的机器指令集和不同的汇编语言。在过去,应用程序必须为每个处理器编写汇编,因此为多个处理器开发应用程序并不容易。在20世纪70年代早期,高级语言(如C)被开发出来,使编写一个简单易懂的代码成为可能,这些代码可以在任何处理器上工作,而无需为每个处理器重写。更具体地说,这是通过为每种语言创建编译器来实现的。
当高级代码被编译时,它被翻译成处理器的汇编指令,然后汇编成机器代码在处理器上运行。这就是为什么编译器是为各种语言和各种处理器构建的,以将高级代码转换为汇编代码,然后转换为与运行的处理器匹配的机器代码。
后来,解释型语言被开发出来,比如Python、PHP、Bash、JavaScript和其他语言,它们通常不被编译,而是在运行时被解释。这些类型的语言利用预构建的库来运行它们的指令。这些库通常是用其他高级语言(如C或C++)编写和编译的。因此,当我们用解释语言发出命令时,它将使用编译库来运行该命令,该命令使用其汇编代码/机器代码来执行在处理器上运行该命令所需的所有指令。
编译阶段

让我们以一个基本的’Hello World!‘程序为例,它将这些单词打印在屏幕上,并展示它如何从高级代码变为机器代码。在解释型语言(如Python)中,它将是以下基本行:
Code:
print("Hello World!") |
如果我们运行这行Python代码,它实际上会执行以下C代码:
Code: 验证码: cC
|
注意:实际的C源代码要长得多,但以上是字符串’Hello World!‘打印的本质。如果你有兴趣了解更多,你可以在这个链接和这个链接上查看Python 3 print函数的源代码。
上面的C代码使用了Linux write系统调用,它内置了进程写入屏幕的功能。在Assembly中调用的相同系统调用如下所示:
Code:
mov rax, 1 |
正如我们所看到的,当在write或Assembly中调用C系统调用时,两者都使用1,文本和12作为参数。这将在本模块的后面部分进行更深入的介绍。从这一点来看,汇编代码、shellcode和二进制机器代码基本上是相同的,但格式不同。前面的汇编代码可以被汇编成下面的十六进制机器代码(即,shellcode):
Code:
48 c7 c0 01 |
最后,为了让处理器执行链接到这台机器的指令,它必须被翻译成二进制,看起来像下面这样:
Code: 验证码: binary二进制
01001000 11000111 11000000 00000001 |
CPU对1和0使用不同的电荷,因此一旦它接收到这些指令,就可以从二进制数据中计算出这些指令。
注意:对于多平台语言,如Java,代码被编译成Java字节码,这对所有处理器/系统都是相同的,然后由本地Java编译环境编译成机器码。这就是为什么Java比其他直接编译成机器码的语言(如C++)相对较慢的原因。像C++这样的语言更适合处理器密集型应用程序,如游戏。
我们现在看到了计算机语言是如何从每个处理器唯一的汇编语言发展到甚至不需要编译就可以在任何设备上工作的高级语言的。
Value for Pentesters Pentesters的价值
理解汇编语言指令对于二进制开发至关重要,二进制开发是渗透测试的重要组成部分。当涉及到利用编译程序时,攻击它们的唯一方法就是通过它们的二进制文件。要反汇编、调试和跟踪内存中的二进制指令并找到潜在的漏洞,我们必须对汇编语言及其如何流经CPU组件有基本的了解。
这就是为什么一旦我们开始学习二进制利用技术,如缓冲区溢出,ROP链,堆利用等,我们将处理大量汇编指令并在内存中遵循它们。此外,要利用这些漏洞,我们必须构建自定义漏洞,使用汇编指令在内存中操作代码并注入要执行的汇编外壳代码。
学习英特尔x86汇编语言对于在现代机器上编写二进制文件的漏洞至关重要。除了Intel x86之外,ARM也变得越来越普遍,因为大多数现代智能手机和一些现代笔记本电脑(如M1 MacBook Pro)都配备了ARM处理器。在这些系统中利用二进制文件需要ARM汇编知识。本模块不包括ARM汇编语言。话虽如此,汇编语言基础无疑对任何愿意学习ARM汇编的人都有帮助,因为这两种语言有很多相似之处。
Computer Architecture
今天,大多数现代计算机都是建立在所谓的冯·诺依曼体系结构上的,该体系结构是由Von Neumann在1945年开发的,以便能够创建“通用计算机”,正如Alan Turing当时所描述的那样。Alan Turing反过来,他的想法基于Charles Babbage的世纪中期的“可编程计算机”概念。请注意,所有这些人都是数学家。
该架构执行机器代码以执行特定算法。它主要包括以下几个要素:
- Central Processing Unit (CPU)
- Memory Unit
- Input/Output Devices
- Mass Storage Unit
- Keyboard
- Display
此外,CPU本身由三个主要组件组成:
- Control Unit (CU)
- Arithmetic/Logic Unit (ALU)
- Registers
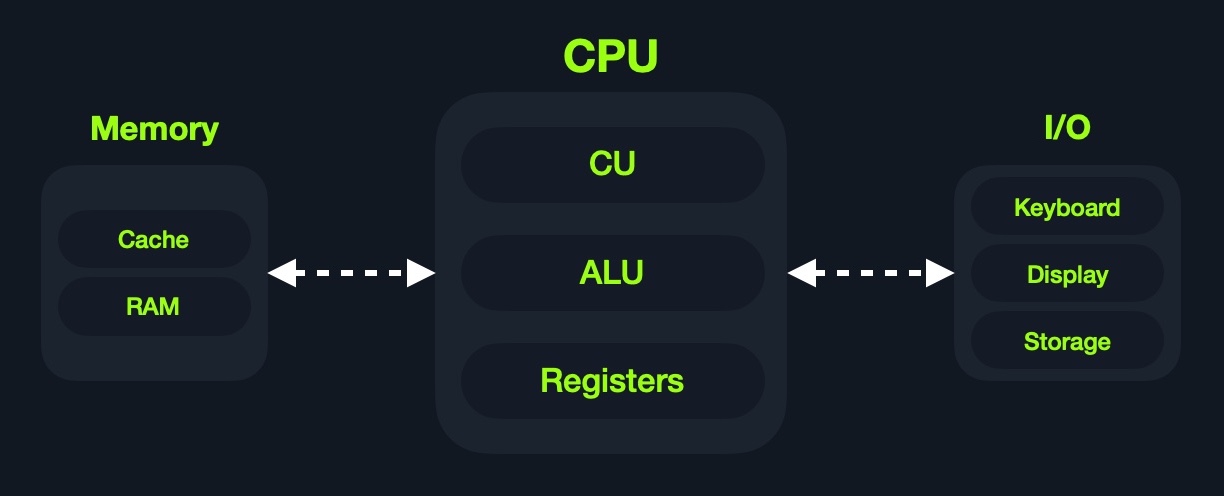
虽然非常古老,但这种架构仍然是大多数现代计算机,服务器甚至智能手机的基础。
汇编语言主要处理CPU和内存。这就是为什么理解计算机体系结构的总体设计至关重要,所以当我们开始使用汇编指令来移动和处理数据时,我们知道它从哪里来,以及每条指令的速度/成本有多高。
此外,基本和高级的二进制开发需要对计算机体系结构有正确的理解。对于基本的堆栈溢出,我们只需要知道一般的设计。一旦我们开始使用ROP和Heap漏洞,我们的理解应该是深刻的。现在让我们更深入地研究一些基本组成部分。
Memory
计算机的内存是当前运行程序的数据和指令所在的地方。计算机的内存也被称为主内存。它是CPU用来检索和处理数据的主要位置。它非常频繁地这样做(每秒数十亿次),因此内存必须在存储和检索数据和指令时非常快。
There are two main types of memory
CacheRandom Access Memory (RAM)
Cache
高速缓存通常位于CPU本身,因此与RAM相比速度非常快,因为它以与CPU相同的时钟速度运行。然而,它的尺寸非常有限,非常复杂,并且由于它非常接近CPU核心而制造成本昂贵。
由于RAM的时钟速度通常比CPU内核慢得多,除了它远离CPU之外,如果CPU必须等待RAM来检索每个指令,它将有效地以低得多的时钟速度运行。这是高速缓存的主要优点。它使CPU能够比从RAM中检索更快地访问即将到来的指令和数据。
通常有三个级别的缓存内存,这取决于它们与CPU核心的接近程度:
| Level | Description |
|---|---|
Level 1 Cache |
Usually in kilobytes, the fastest memory available, located in each CPU core. (Only registers are faster.) |
Level 2 Cache |
Usually in megabytes, extremely fast (but slower than L1), shared between all CPU cores.通常以兆字节为单位,非常快(但比L1慢),在所有CPU内核之间共享。 |
Level 3 Cache Level 1 Cache |
Usually in megabytes (larger than L2), faster than RAM but slower than L1/L2. (Not all CPUs use L3.) |
RAM
RAM比高速缓存大得多,大小从千兆字节到兆兆字节不等。RAM也位于远离CPU核心的位置,并且比缓存慢得多。从RAM地址读取数据需要更多的指令。
例如,从寄存器中检索一条指令只需要一个时钟周期,从L1缓存中检索它需要几个周期,而从RAM中检索它需要大约200个周期。当每秒执行数十亿次时,它会在整体执行速度上产生巨大的差异。
在过去,对于32位地址,存储器地址被限制在0x00000000到0xffffffff之间。这意味着最大可能的RAM大小是232字节,也就是只有4GB,此时我们将用完唯一地址。使用64位地址,范围现在达到0xffffffffffffffff,理论上最大RAM大小为264字节,约为18.5艾字节(1850万TB),因此我们应该不会很快用完内存地址。
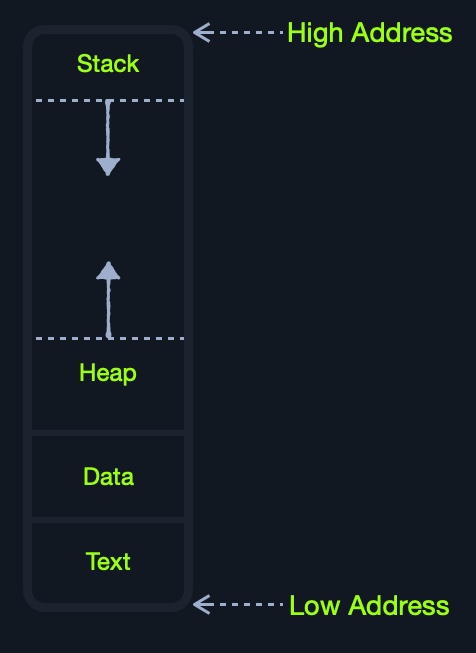
当一个程序运行时,它的所有数据和指令都从存储单元移动到RAM,以便CPU在需要时访问。这是因为从存储单元访问它们要慢得多,并且会增加数据处理时间。当程序关闭时,其数据将从RAM中删除或重新使用。
正如我们所看到的,RAM分为四个主要的segments:
| Segment | Description |
|---|---|
Stack Level 1 Cache |
有后进先出(LIFO)设计,大小固定。其中的数据只能通过推送和弹出数据以特定的顺序访问。 |
Heap Level 1 Cache |
具有分层设计,因此在存储数据方面更大,更通用,因为数据可以以任何顺序存储和检索。然而,这使得堆比堆栈慢。 |
Data Level 1 Cache |
有两个部分:Data,用于保存变量,.bss,用于保存未赋值的变量(即,用于以后分配的缓冲存储器)。 |
Text Level 1 Cache |
主汇编指令被加载到这个段中,由CPU获取和执行。 |
尽管这种分段适用于整个RAM,但each application is allocated its Virtual Memory when it is run。这意味着每个应用程序都有自己的stack、heap、data和text段。
IO/Storage IO/存储
最后,我们有输入/输出设备,如键盘,屏幕或长期存储单元,也称为辅助存储器。处理器可以使用Bus Interfaces访问和控制IO设备,这些设备充当传输数据和地址的“高速公路”,使用二进制数据的电荷。
每条总线都有一个可以同时承载的比特(或电荷)容量。这通常是4位的倍数,范围高达128位。总线接口通常也用于访问内存和CPU本身之外的其他组件。如果我们仔细观察CPU或主板,我们可以看到它们上面的总线接口:

与易失性的主存储器不同,存储单元存储永久数据,如操作系统文件或整个应用程序及其数据。
存储单元访问速度最慢。首先,因为它们离CPU最远,通过SATA或USB等总线接口访问它们需要更长的时间来存储和检索数据。它们在设计上也较慢,以允许更多的数据存储。只要有更多的数据要通过,它们就会慢一些。
近年来,已经从传统的磁性存储单元(如磁带或硬盘驱动器(HDD))转向固态驱动器(SSD)。这是因为SSD使用与RAM类似的设计,使用非易失性电路,即使没有电力也可以保留数据。这使得存储单元在存储和检索数据时更快。尽管如此,由于它们远离CPU并通过特殊接口连接,它们是访问速度最慢的单元。
Speed 速度
从上面可以看出,组件离CPU核心越远,它就越慢。此外,它可以容纳的数据越多,它就越慢,因为它只需要通过更多的数据来获取数据。下表总结了每个组件及其大小和速度:
| Component | Speed | Size |
|---|---|---|
Registers Level 1 Cache |
Fastest | Bytes |
L1 Cache Level 1 Cache |
Fastest, other than Registers | Kilobytes |
L2 Cache Level 1 Cache |
Very fast | Megabytes |
L3 Cache Level 1 Cache |
Fast, but slower than the above | Megabytes |
RAM Level 1 Cache |
Much slower than all of the above | Gigabytes-Terabytes |
Storage Level 1 Cache |
Slowest | Terabytes and more |
这里的速度是相对的,取决于CPU的时钟速度。现在我们对计算机体系结构有了一个大致的了解,我们将在下一节讨论寄存器和CPU体系结构。
CPU Architecture
中央处理器(CPU)是计算机中的主要处理单元。CPU包含负责移动和控制数据的Control Unit(CU)和负责执行程序通过汇编指令请求的各种算术和逻辑计算的Arithmetic/Logic Unit(ALU)。
CPU处理指令的方式和效率取决于它的Instruction Set Architecture。行业中有多种ISA,每种ISA都有其处理数据的方式。RISC架构基于处理更简单的指令,这需要更多的周期,但每个周期更短,功耗更低。CISC架构基于更少、更复杂的指令,可以在更少的周期内完成所请求的指令,但每条指令需要更多的时间和功率来处理。
让我们看看RISC和CISC,并了解更多关于指令周期和寄存器的信息。
Clock Speed & Clock Cycle
每个CPU都有一个时钟速度来表示其整体速度。时钟的每一个滴答都运行一个时钟周期,处理一条基本指令,如获取地址或存储地址。具体来说,这是由CU或ALU完成的。
循环发生的频率被计数为每秒循环(Hertz)。如果CPU的速度为3.0 GHz,则每秒可以运行30亿个周期(每个核心)。
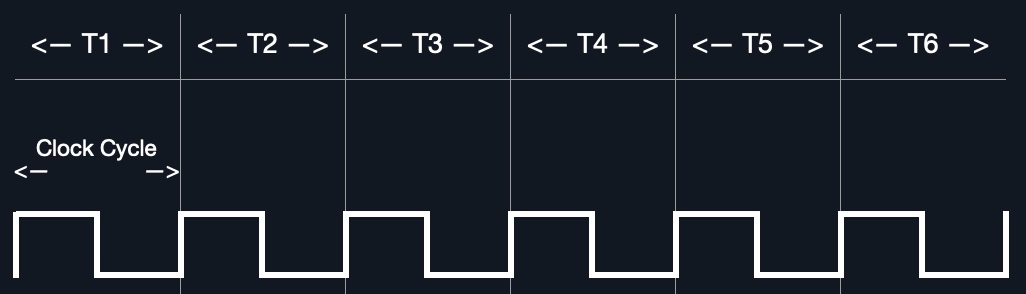
现代处理器具有多核设计,允许它们同时具有多个周期。
Instruction Cycle
Instruction Cycle是CPU处理单个机器指令所需的周期。
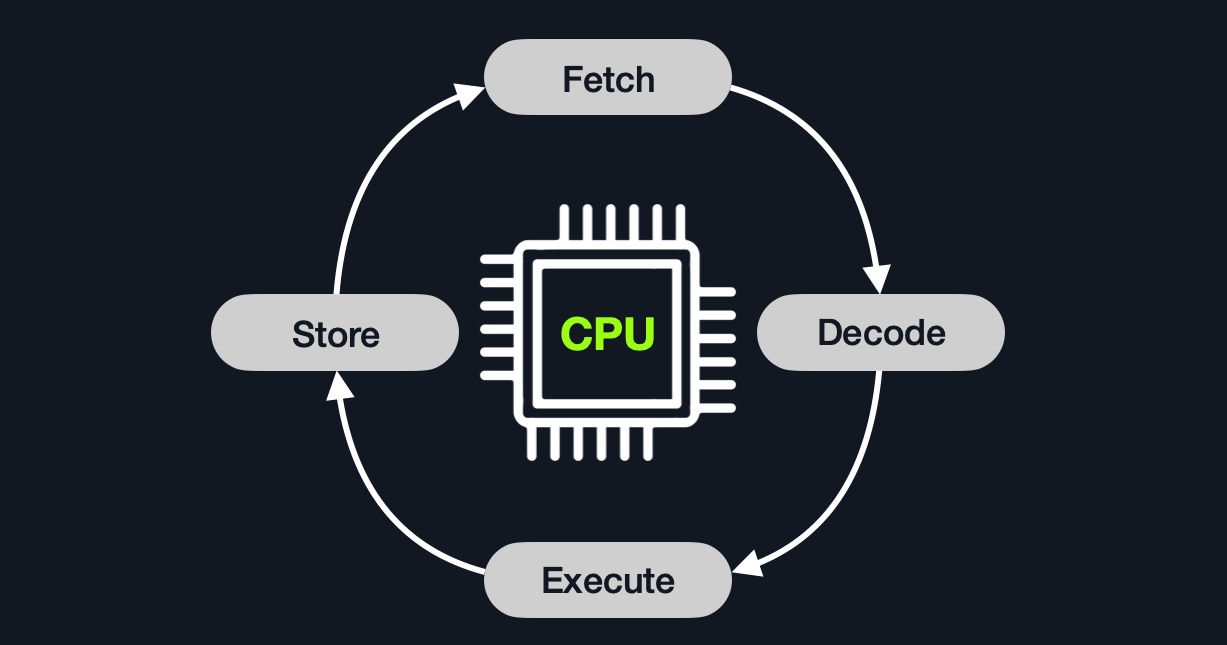
一个指令周期由四个阶段组成:Fetch、Decode、Execute和Store:
| Instruction | Description |
|---|---|
1. Fetch 3. Execute |
从Instruction Address Register(IAR)中获取下一条指令的地址,该地址告诉它下一条指令的位置。 |
2. Decode |
从IAR获取指令,并将其从二进制解码,以查看需要执行的内容。 |
3. Execute |
从寄存器/存储器中获取指令操作数,并在ALU或CU中处理指令。 |
4. Store 3. Execute |
将新值存储在目标操作数中。 |
指令周期中的所有阶段都由控制单元执行,除非需要执行算术指令“加、减、.”。等等”,由ALU执行。
每个指令周期需要多个时钟周期才能完成,具体取决于CPU架构和指令的复杂性。一旦单个指令周期结束,CU递增到下一个指令并对其运行相同的周期,依此类推。
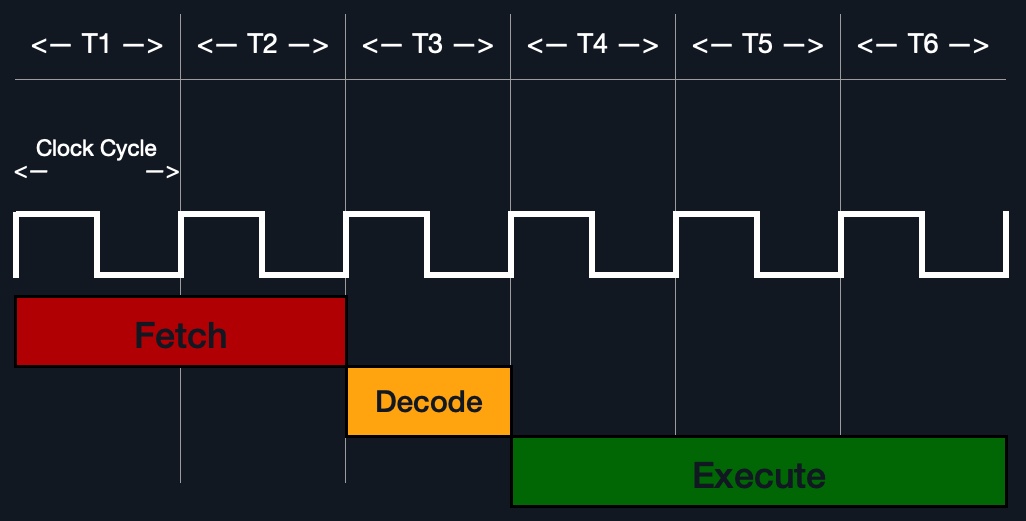
例如,如果我们要执行汇编指令add rax, 1,它将运行一个指令周期:
- 从
rip寄存器48 83 C0 01(二进制)中获取指令。 - 解码“
48 83 C0 01”以知道它需要对add处的值执行1的rax。 - 在
rax(通过CU)获得当前值,将1添加到它(通过ALU)。 - 将新值存储回
rax。
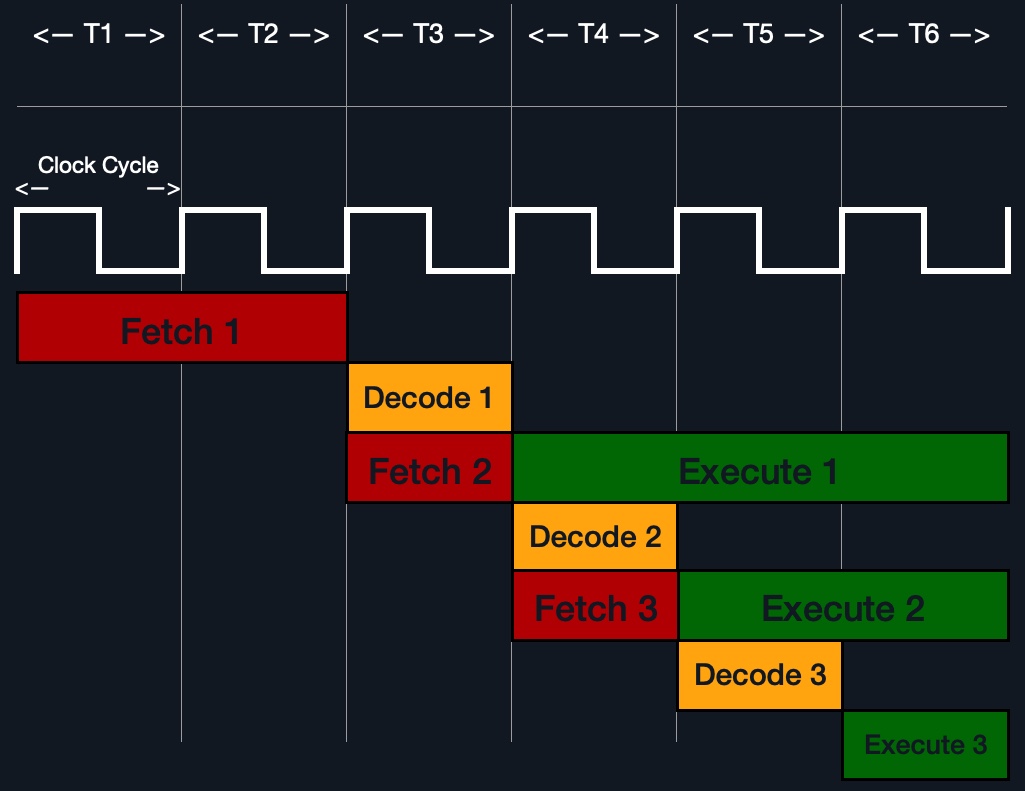
在过去,处理器习惯于顺序处理指令,因此它们必须等待一条指令完成才能开始下一条指令。另一方面,现代处理器可以通过同时运行多个指令/时钟周期来并行处理多个指令。这是通过多线程和多核设计实现的。
Processor Specific
如前所述,每个处理器理解不同的指令集。例如,虽然基于64位x86架构的Intel处理器可以将机器代码4883C001解释为add rax, 1,但是ARM处理器将相同的机器代码翻译为biceq r8, r0, r8, asr #6指令。正如我们所看到的,相同的机器代码在每个处理器上执行完全不同的指令。
这是因为每种处理器类型都有不同的低级汇编语言架构,称为Instruction Set ArchitecturesISA。例如,上面看到的add指令add rax, 1用于Intel x86 64位处理器。为ARM处理器汇编语言编写的相同指令表示为add r1, r1, 1。
It is important to understand that each processor has its own set of instructions and corresponding machine code. |
此外,单个指令集架构可以具有用于相同汇编代码的若干语法解释。例如,上面的add指令基于x86架构,其由多个处理器(如Intel、AMD和传统AT T处理器)支持。该指令使用Intel语法编写为add rax, 1,使用AT T语法编写为addb $0x1,%rax。
正如我们所看到的,尽管我们可以看出这两条指令是相似的,并且做同样的事情,但它们的语法是不同的,并且源操作数和目标操作数的位置也被交换了。尽管如此,这两种代码汇编相同的机器码并执行相同的指令。
So, each processor type has its Instruction Set Architectures, and each architecture can be further represented in several syntax formats |
本模块将主要关注英特尔x86 64位汇编语言(也称为x86_64和AMD 64),因为大多数现代计算机和服务器都运行在这种处理器架构上。我们也将使用Intel语法。
如果我们想知道我们的Linux系统是否支持x86_64架构,我们可以使用lscpu命令:
mikannse7@htb[/htb]$ lscpu |
正如我们在上面的输出中所看到的,CPU架构是x86_64,支持32位和64位。字节顺序是小端。我们也可以使用uname -m命令来获取CPU架构。我们将在下一节讨论两种最常见的指令集架构:CISC和RISC。
指令集架构
Instruction Set Architecture(ISA)指定了每个体系结构上汇编语言的语法和语义。它不仅仅是一种不同的语法,而是内置在处理器的核心设计中,因为它影响指令执行的方式和顺序以及它们的复杂程度。ISA主要由以下组件组成:
- Instructions
- Registers
- Memory Addresses
- Data Types
| Component | Description | Example |
|---|---|---|
Instructions |
要以opcode operand_list格式处理的指令。通常有1、2或3个逗号分隔的操作数。 |
add rax, 1, mov rsp, rax, push rax add rax, 1、mov rsp, rax、push rax |
Registers |
用于临时存储操作数、地址或指令。 | rax, rsp, rip rax、rsp、rip |
Memory Addresses |
存储数据或指令的地址。可能指向内存或寄存器。 | 0xffffffffaa8a25ff, 0x44d0, $rax 0xffffffffaa8a25ff、0x44d0、$rax |
Data Types |
存储数据的类型。 | byte, word, double word byte、word、double word |
这些是区分不同ISA和汇编语言的主要组件。我们将在接下来的章节中更深入地介绍它们中的每一个,并学习如何使用各种指令。
有两种主要的指令集架构被广泛使用:
Complex Instruction Set Computer(CISC)-用于大多数计算机和服务器的Intel和AMD处理器。Reduced Instruction Set Computer(RISC)-用于ARM和Apple处理器,大多数智能手机和一些现代笔记本电脑。
让我们看看每一个的优点和缺点,以及它们之间的主要区别。
CISC
CISC架构是ISA最早开发的架构之一。顾名思义,CISC体系结构倾向于一次运行更复杂的指令,以减少指令的总数。这样做是为了尽可能多地依赖于CPU,将次要指令组合成更复杂的指令。
例如,假设我们要用“add rax, rbx”指令添加两个寄存器。在这种情况下,CISC处理器可以在单个“Fetch-Decode-Execute-Store”指令周期中完成此操作,而不必将其拆分为多个指令来获取rax,然后获取rbx,然后将它们添加,然后将它们存储在“rax”中,每个指令都将占用自己的“Fetch-Decode-Execute-Store”指令周期。
主要有两个原因:
- 通过将处理器设计为在其核心中运行更高级的指令,使更多的指令能够同时执行。
- 在过去,内存和晶体管是有限的,所以更倾向于通过将多条指令合并为一条来编写较短的程序。
为了使处理器能够执行复杂的指令,处理器的设计变得更加复杂,因为它被设计为执行大量不同的复杂指令,每个复杂指令都有自己的单元来执行它。
此外,尽管执行单个指令需要单个指令周期,但是由于指令更复杂,每个指令周期需要更多的时钟周期。这一事实导致更多的功耗和热量来执行每个指令。
RISC
RISC架构倾向于将指令分割成小指令,因此CPU仅被设计为处理简单指令。这样做是为了通过编写最优化的汇编代码将优化传递给软件。
例如,RISC处理器上的相同的前一个add r1, r2, r3指令将获取r2,然后获取r3,将它们相加,最后将它们存储在r1中。这些指令中的每一条都需要一个完整的“提取-解码-执行-存储”指令周期,这导致每个程序的总指令数更大,因此汇编代码更长。
由于不支持各种类型的复杂指令,与CISC处理器(~200)相比,RISC处理器只支持有限数量的指令(~1500)。因此,要执行复杂的指令,这必须通过汇编的次要指令组合来完成。
据说我们可以用一个只支持一条指令的处理器来建造一台通用计算机!这表明我们可以只使用sub指令来创建非常复杂的指令。你能想到如何实现这一点吗?
另一方面,将复杂指令分割成次要指令的优点是使所有指令的长度相同,或者是32位,或者是64位。这使得CPU的时钟速度能够围绕指令长度进行设计,以便执行指令周期中的每个阶段总是精确地占用一个机器时钟周期。
下图显示了CISC指令如何占用可变数量的时钟周期,而RISC指令占用固定数量的时钟周期: 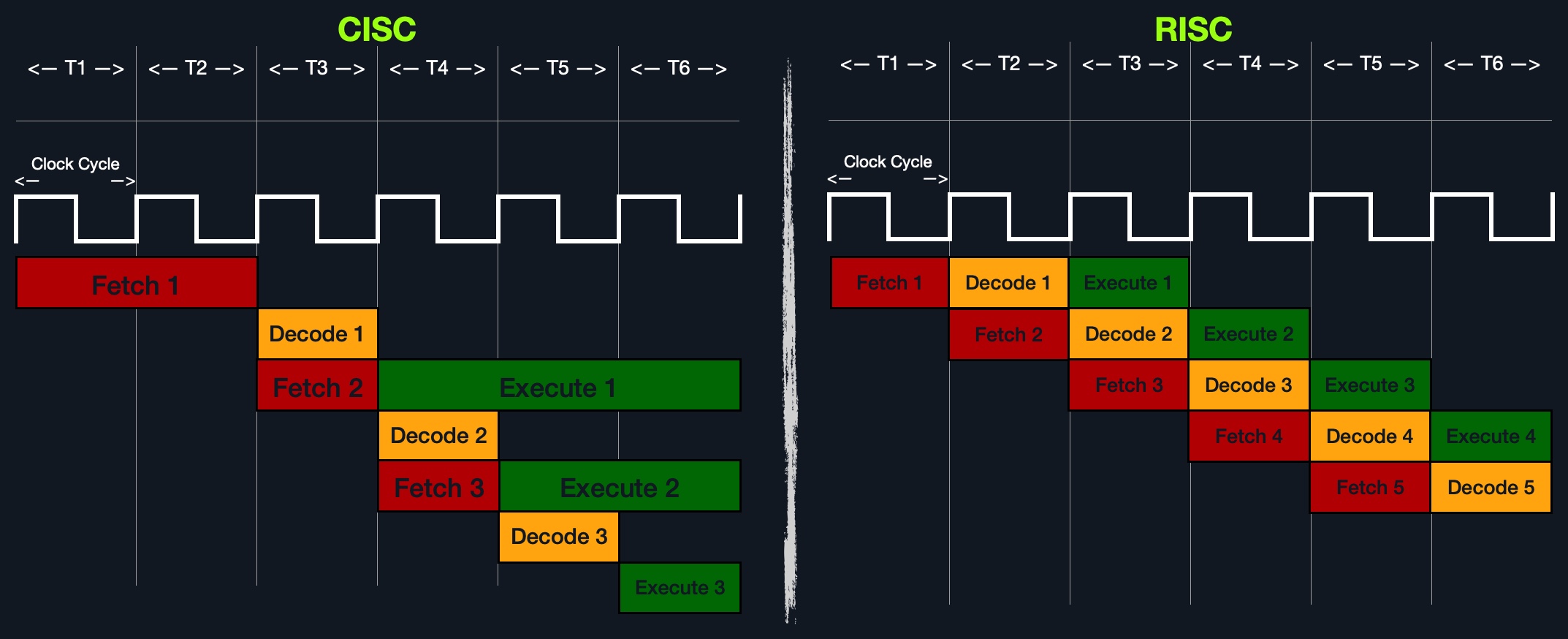
在单个时钟周期内执行每个指令阶段,并且只执行简单的指令,导致RISC处理器消耗CISC处理器所消耗的一小部分功率,这使得这些处理器非常适合使用电池运行的设备,如智能手机和笔记本电脑。
CISC vs. RISC
下表总结了CISC和RISC之间的主要区别:
| Area区域 | CISC | RISC |
|---|---|---|
Complexity Instructions |
支持复杂指令 | 支持简单指令 |
Length of instructions Instructions |
更长的指令-可变长度“8位的倍数” | 更短的指令-固定长度“32位/64位” |
Total instructions per program Instructions |
指令总数更少-代码更短 | 更多总指令-更长的代码 |
Optimization Instructions |
依赖于硬件优化(在CPU中) | 依赖于软件优化(在装配中) |
Instruction Execution Time Instructions |
变量-多个时钟周期 | 固定-一个时钟周期 |
Instructions supported by CPU Instructions |
许多指令(~1500) | 更少的指令(~200) |
Power Consumption Instructions |
High | Very low |
Examples Instructions |
Intel, AMD | ARM, Apple |
在过去,由于每个程序的总指令数量较多,因此汇编代码较长,这对于RISC处理器来说是一个显著的缺点,因为内存和存储资源有限。然而,今天这不再是一个大问题,因为内存和存储不像过去那样昂贵和有限。
此外,随着新的汇编器和编译器在软件层面上编写极其优化的代码,RISC处理器变得比CISC处理器更快,即使在执行和处理繁重的应用程序时,所有这些都消耗更少的功率。
所有这些都使得RISC处理器在近年来更加普遍。RISC可能在未来几年成为主导架构。但正如我们所说,我们将测试的绝大多数计算机和服务器都运行在具有CISC架构的英特尔/AMD处理器上,因此学习CISC组装是我们的首要任务。由于所有汇编语言变体的基础都非常相似,因此在完成本模块后,学习ARM汇编应该会更加简单。
Registers, Addresses, and Data Types
现在我们已经了解了通用计算机和处理器架构,在开始学习汇编之前,我们需要了解一些汇编元素:Registers,Memory Addresses,Address Endianness和Data Types。这些元素中的每一个都很重要,正确理解它们将帮助我们在编写和调试汇编代码时避免问题和故障排除时间。
Registers
如前所述,每个CPU内核都有一组寄存器。寄存器是任何计算机中最快的组件,因为它们内置在CPU内核中。然而,寄存器的大小非常有限,一次只能保存几个字节的数据。x86架构中有很多寄存器,但我们只关注学习基本汇编所必需的寄存器,以及未来二进制开发所必需的寄存器。
我们将重点关注两种主要类型的寄存器:Data Registers和Pointer Registers。
| Data Registers | Pointer Registers |
|---|---|
rax |
rbp |
rbx |
rsp |
rcx |
rip |
rdx |
|
r8 |
|
r9 |
|
r10 |
Data Registers-通常用于存储指令/系统调用参数。主数据寄存器为:rax、rbx、rcx和rdx。rdi和rsi寄存器也存在,通常用于指令destination和source操作数。然后,我们有辅助数据寄存器,可以在所有先前的寄存器都在使用时使用,它们是r8、r9和r10。Pointer Registers-用于存储特定的重要地址指针。主指针寄存器是指向堆栈开始的基本堆栈指针rbp、指向堆栈内的当前位置(堆栈顶部)的当前堆栈指针rsp以及保存下一指令的地址的指令指针rip。
Sub-Registers
每个64-bit寄存器可以进一步划分为包含低位的更小的子寄存器,在一个字节8-bits、2个字节16-bits和4个字节32-bits。每个子寄存器都可以单独使用和访问,因此如果数据量较少,我们不必使用全部64位。

子寄存器可以通过以下方式访问:
| Size in bits | Size in bytes | Name | Example |
|---|---|---|---|
16-bit rcx |
2 bytes rcx |
the base name | ax rcx |
8-bit rcx |
1 bytes rcx |
base name and/or ends with l |
al rcx |
32-bit rcx |
4 bytes rcx |
base name + starts with the e prefix |
eax rcx |
64-bit rcx |
8 bytes rcx |
base name + starts with the r prefix |
rax rcx |
例如,对于bx数据寄存器,16位为bx,因此8位为bl,32位为ebx,64位为rbx。指针寄存器也是如此。如果我们取基本堆栈指针bp,它的16位子寄存器是bp,因此8位是bpl,32位是ebp,64位是rbp。
以下是x86_64架构中所有基本寄存器的子寄存器名称:
| Description | 64-bit Register64 | 32-bit Register32 | 16-bit Register16 | 8-bit Register8- |
|---|---|---|---|---|
| Data/Arguments Registers | ||||
| Syscall Number/Return value | rax rcx |
eax rcx |
ax rcx |
al rcx |
| Callee Saved | rbx rcx |
ebx rcx |
bx rcx |
bl rcx |
| 1st arg - Destination operand | rdi rcx |
edi rcx |
di rcx |
dil rcx |
| 2nd arg - Source operand | rsi rcx |
esi rcx |
si rcx |
sil rcx |
| 3rd arg | rdx rcx |
edx rcx |
dx rcx |
dl rcx |
| 4th arg - Loop counter4th arg | rcx |
ecx rcx |
cx rcx |
cl rcx |
| 5th arg | r8 rcx |
r8d rcx |
r8w rcx |
r8b rcx |
| 6th arg | r9 rcx |
r9d rcx |
r9w rcx |
r9b rcx |
| Pointer Registers | ||||
| Base Stack Pointer | rbp rcx |
ebp rcx |
bp rcx |
bpl rcx |
| Current/Top Stack Pointer | rsp rcx |
esp rcx |
sp rcx |
spl rcx |
| Instruction Pointer ‘call only | rip rcx |
eip rcx |
ip rcx |
ipl rcx |
在学习本模块时,我们将讨论如何使用这些寄存器。
还有其他各种寄存器,但我们不会在本模块中介绍它们,因为它们对于基本的汇编用法来说并不需要。例如,有RFLAGS寄存器,用于维护CPU使用的各种标志,如零标志ZF,用于条件指令。
Memory Addresses
如前所述,x86 64位处理器具有64位宽的地址,范围从0x0到0xffffffffffffffff,因此我们期望地址在此范围内。然而,RAM被分割成不同的区域,如堆栈、堆和其他程序和内核特定的区域。每个内存区域都有特定的read、write、execute权限,指定我们是否可以从中读取、写入或调用其中的地址。
每当一条指令通过指令周期被执行时,第一步是从它所在的地址获取指令,如前所述。存在几种类型的地址获取(即,寻址模式)在x86体系结构中:
| Addressing Mode | Description | Example |
|---|---|---|
Immediate rcx |
该值在指令中给出 | add 2 rcx |
Register rcx |
保存该值的寄存器名称在指令中给出 | add rax rcx |
Direct rcx |
直接完整地址在指令中给出 | call 0xffffffffaa8a25ff rcx |
Indirect rcx |
在指令中给出一个引用指针 | call 0x44d000 or call [rax] call 0x44d000或call [rax] |
Stack rcx |
地址位于堆栈顶部 | add rsp rcx |
在上表中,越低越慢。值的即时性越低,获取它的速度就越慢。
尽管速度不是我们在学习基本汇编语言时最关心的问题,但我们应该了解每个地址的位置和方式。了解这些将有助于我们在未来的二进制攻击中,例如缓冲区溢出攻击。同样的理解将对高级二进制开发(如ROP或Heap开发)产生更重要的影响。
地址Endianness
地址的字节顺序是它们存储或从内存中检索的字节顺序。有两种类型的endianness:Little-Endian和Big-Endian。对于小端处理器,地址的小端字节首先填充/检索right-to-left,而对于大端处理器,大端字节首先填充/检索left-to-right。
例如,如果我们将地址0x0011223344556677存储在内存中,小端处理器将在最右边的字节上存储0x00字节,然后在它之后填充0x11字节,因此它变成0x1100,然后是0x22字节,因此它变成0x221100,等等。这是原始值的倒数。当然,当检索回值时,处理器也将使用little-endian检索,因此检索到的值将与原始值相同。
另一个显示这如何影响存储值的例子是二进制。例如,如果我们有一个2字节整数426,它的二进制表示是00000001 10101010。这两个字节的存储顺序将改变其值。例如,如果我们将其反向存储为10101010 00000001,则其值变为43521。
大端处理器将这些字节存储为00000001 10101010``left-to-right,而小端处理器将它们存储为10101010 00000001``right-to-left。当检索值时,处理器必须使用与存储它们时相同的字节序,否则它将得到错误的值。这表明存储/检索字节的顺序有很大的不同。
现在我们已经了解了通用计算机和处理器架构,在开始学习汇编之前,我们需要了解一些汇编元素:Registers,Memory Addresses,Address Endianness和Data Types。这些元素中的每一个都很重要,正确理解它们将帮助我们在编写和调试汇编代码时避免问题和故障排除时间。
Registers
如前所述,每个CPU内核都有一组寄存器。寄存器是任何计算机中最快的组件,因为它们内置在CPU内核中。然而,寄存器的大小非常有限,一次只能保存几个字节的数据。x86架构中有很多寄存器,但我们只关注学习基本汇编所必需的寄存器,以及未来二进制开发所必需的寄存器。
我们将重点关注两种主要类型的寄存器:Data Registers和Pointer Registers。
| Data Registers数据寄存器 | Pointer Registers指针寄存器 |
|---|---|
rax |
rbp |
rbx |
rsp |
rcx |
rip |
rdx |
|
r8 |
|
r9 |
|
r10 |
Data Registers-通常用于存储指令/系统调用参数。主数据寄存器为:rax、rbx、rcx和rdx。rdi和rsi寄存器也存在,通常用于指令destination和source操作数。然后,我们有辅助数据寄存器,可以在所有先前的寄存器都在使用时使用,它们是r8、r9和r10。Pointer Registers-用于存储特定的重要地址指针。主指针寄存器是指向堆栈开始的基本堆栈指针rbp、指向堆栈内的当前位置(堆栈顶部)的当前堆栈指针rsp以及保存下一指令的地址的指令指针rip。
Sub-Registers 子寄存器
每个64-bit寄存器可以进一步划分为包含低位的更小的子寄存器,在一个字节8-bits、2个字节16-bits和4个字节32-bits。每个子寄存器都可以单独使用和访问,因此如果数据量较少,我们不必使用全部64位。
子寄存器可以通过以下方式访问:
| Size in bits大小(位) | Size in bytes字节大小 | Name名称 | Example例如 |
|---|---|---|---|
16-bit rcx |
2 bytes rcx |
the base name站点名称 | ax rcx |
8-bit rcx |
1 bytes rcx |
base name and/or ends with l 基本名称和/或以l结尾 |
al rcx |
32-bit rcx |
4 bytes rcx |
base name + starts with the e prefix 基本名称+以r前缀开头 |
eax rcx |
64-bit rcx |
8 bytes rcx |
base name + starts with the r prefix 基本名称+以r前缀开头 |
rax rcx |
例如,对于bx数据寄存器,16位为bx,因此8位为bl,32位为ebx,64位为rbx。指针寄存器也是如此。如果我们取基本堆栈指针bp,它的16位子寄存器是bp,因此8位是bpl,32位是ebp,64位是rbp。
以下是x86_64架构中所有基本寄存器的子寄存器名称:
| Description描述 | 64-bit Register64-位寄存器 | 32-bit Register32-位寄存器 | 16-bit Register16-位寄存器 | 8-bit Register8-位寄存器 |
|---|---|---|---|---|
| Data/Arguments Registers 数据/参数寄存器 | ||||
| Syscall Number/Return value系统调用编号/返回值 | rax rcx |
eax rcx |
ax rcx |
al rcx |
| Callee Saved调用者保存 | rbx rcx |
ebx rcx |
bx rcx |
bl rcx |
| 1st arg - Destination operand第一个参数-目标操作数 | rdi rcx |
edi rcx |
di rcx |
dil rcx |
| 2nd arg - Source operand第二个参数-源操作数 | rsi rcx |
esi rcx |
si rcx |
sil rcx |
| 3rd arg第三个参数 | rdx rcx |
edx rcx |
dx rcx |
dl rcx |
| 4th arg - Loop counter4th arg -循环计数器 | rcx |
ecx rcx |
cx rcx |
cl rcx |
| 5th arg第五个参数 | r8 rcx |
r8d rcx |
r8w rcx |
r8b rcx |
| 6th arg第六个参数 | r9 rcx |
r9d rcx |
r9w rcx |
r9b rcx |
| Pointer Registers 指针寄存器 | ||||
| Base Stack Pointer基本堆栈指针 | rbp rcx |
ebp rcx |
bp rcx |
bpl rcx |
| Current/Top Stack Pointer当前/顶部堆栈指针 | rsp rcx |
esp rcx |
sp rcx |
spl rcx |
| Instruction Pointer ‘call only’指令指针“仅调用” | rip rcx |
eip rcx |
ip rcx |
ipl rcx |
在学习本模块时,我们将讨论如何使用这些寄存器。
还有其他各种寄存器,但我们不会在本模块中介绍它们,因为它们对于基本的汇编用法来说并不需要。例如,有RFLAGS寄存器,用于维护CPU使用的各种标志,如零标志ZF,用于条件指令。
Memory Addresses
如前所述,x86 64位处理器具有64位宽的地址,范围从0x0到0xffffffffffffffff,因此我们期望地址在此范围内。然而,RAM被分割成不同的区域,如堆栈、堆和其他程序和内核特定的区域。每个内存区域都有特定的read、write、execute权限,指定我们是否可以从中读取、写入或调用其中的地址。
每当一条指令通过指令周期被执行时,第一步是从它所在的地址获取指令,如前所述。存在几种类型的地址获取(即,寻址模式)在x86体系结构中:
| Addressing Mode | Description | Example |
|---|---|---|
Immediate rcx |
The value is given within the instruction | add 2 rcx |
Register rcx |
保存该值的寄存器名称在指令中给出 | add rax rcx |
Direct rcx |
直接完整地址在指令中给出 | call 0xffffffffaa8a25ff rcx |
Indirect rcx |
在指令中给出一个引用指针 | call 0x44d000 or call [rax] call 0x44d000或call [rax] |
Stack rcx |
地址位于堆栈顶部 | add rsp rcx |
在上表中,越低越慢。值的即时性越低,获取它的速度就越慢。
尽管速度不是我们在学习基本汇编语言时最关心的问题,但我们应该了解每个地址的位置和方式。了解这些将有助于我们在未来的二进制攻击中,例如缓冲区溢出攻击。同样的理解将对高级二进制开发(如ROP或Heap开发)产生更重要的影响。
地址Endianness
地址的字节顺序是它们存储或从内存中检索的字节顺序。有两种类型的endianness:Little-Endian和Big-Endian。对于小端处理器,地址的小端字节首先填充/检索right-to-left,而对于大端处理器,大端字节首先填充/检索left-to-right。
例如,如果我们将地址0x0011223344556677存储在内存中,小端处理器将在最右边的字节上存储0x00字节,然后在它之后填充0x11字节,因此它变成0x1100,然后是0x22字节,因此它变成0x221100,等等。这是原始值的倒数。当然,当检索回值时,处理器也将使用little-endian检索,因此检索到的值将与原始值相同。
另一个显示这如何影响存储值的例子是二进制。例如,如果我们有一个2字节整数426,它的二进制表示是00000001 10101010。这两个字节的存储顺序将改变其值。例如,如果我们将其反向存储为10101010 00000001,则其值变为43521。
大端处理器将这些字节存储为00000001 10101010``left-to-right,而小端处理器将它们存储为10101010 00000001``right-to-left。当检索值时,处理器必须使用与存储它们时相同的字节序,否则它将得到错误的值。这表明存储/检索字节的顺序有很大的不同。
Assembling & Debugging
程序集文件结构
当我们在接下来的章节中学习各种汇编指令时,我们将不断地编写代码,汇编它,并调试它。这是学习每条指令做什么的最好方法。因此,我们需要学习汇编代码文件的基本结构,然后对其进行汇编和调试。
在本节中,我们将介绍Assembly文件的基本结构,在接下来的两节中,我们将介绍Assembly文件的组装和调试。我们将使用模板Hello World! Assembly代码作为示例,首先学习Assembly文件的一般结构,然后学习如何组装和调试它。让我们从查看和剖析示例Hello World! Assembly代码模板开始:
Code:
global _start |
这个汇编代码(一旦汇编和链接)应该将字符串’Hello HTB Academy!‘打印到屏幕上。我们还不会详细讨论如何处理它,但是我们需要理解代码模板的主要元素。
程序集文件结构
首先,让我们看看代码的分发方式:
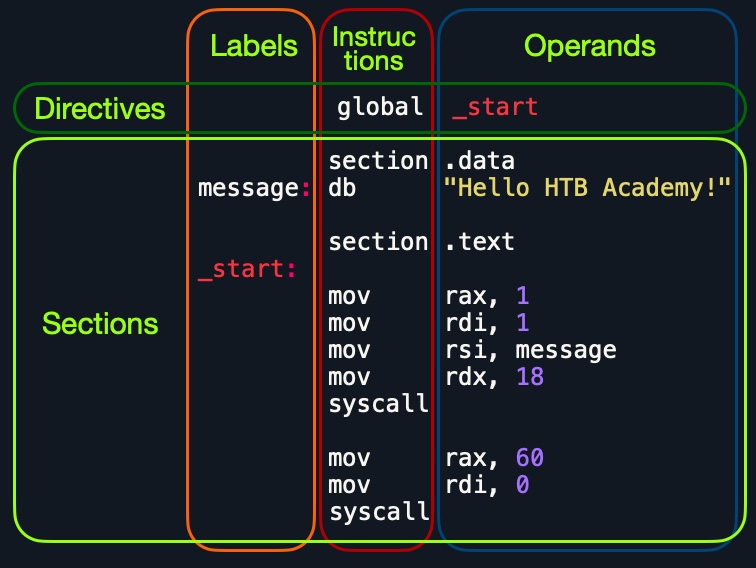
查看代码的垂直部分,每行可以包含三个元素:
1. Labels |
2. Instructions |
3. Operands |
|---|---|---|
我们已经在前面的章节中讨论了instructions和它们的operands,我们将在接下来的章节中详细介绍各种汇编指令。除此之外,我们还可以在每一行定义一个label。每个标签都可以用instructions或directives表示。
接下来,如果我们逐行查看代码,我们会看到它有三个主要部分:
| Section | Description |
|---|---|
global _start |
这是一个directive,它指示代码从下面定义的_start标签开始执行。 |
section .data |
这是data部分,它应该包含所有变量。 |
section .text |
这是包含所有要执行的代码的text部分。 |
.data和.text部分都涉及将存储这些指令的data和text存储器段。
指令
汇编代码是基于行的,这意味着文件是逐行处理的,执行每行的指令。我们在第一行看到一个指令global _start,它指示机器开始处理_start标签之后的指令。因此,机器转到_start标签并开始执行那里的指令,这将在屏幕上打印消息。这将在Control Instructions部分中更详细地介绍。
变量
接下来是.data部分。data部分保存了我们的变量,使我们更容易定义变量并重用它们,而无需多次编写它们。一旦我们运行我们的程序,我们所有的变量将被加载到内存中的data段。
当我们运行程序时,它会将我们定义的任何变量加载到内存中,以便在我们调用它们时可以使用它们。我们将在模块的后面注意到,当我们开始执行_start标签处的指令时,所有变量都已经加载到内存中。
我们可以使用db来定义一个字节列表,dw来定义一个单词列表,dd来定义一个数字列表,等等。我们还可以标记任何变量,以便我们以后可以调用或引用它。以下是定义变量的一些示例:
| Instruction | Description |
|---|---|
db 0x0a section .data |
定义字节0x0a,这是一个新行。 |
message db 0x41, 0x42, 0x43, 0x0a section .data |
定义标签message => abc\n。 |
message db "Hello World!", 0x0a section .data |
定义标签message => Hello World!\n。 |
此外,我们可以使用equ指令和$令牌来计算表达式,例如定义变量字符串的长度。但是,用equ指令定义的标签是常量,以后不能更改。
例如,下面的代码定义了一个变量,然后为其长度定义了一个常量:
Code:
section .data |
注意:$标记表示当前距离当前部分的开始处。由于message变量位于data部分的开头,因此当前位置,即。$的值,等于字符串的长度。对于这个模块的范围,我们将只使用这个标记来计算字符串的长度,使用上面显示的同一行代码。
Code
第二个(也是最重要的)部分是.text部分。这个部分保存所有的汇编指令,并将它们加载到text内存段。一旦所有指令都被加载到text段中,处理器就开始一个接一个地执行它们。
默认的约定是在_start部分的开头使用.text标签,根据global _start指令,该标签开始将在程序运行时执行的主代码。正如我们将在本模块后面看到的,我们可以在.text部分中定义其他标签,用于循环和其他函数。
内存中的text段是只读的,所以我们不能在其中写入任何变量。另一方面,data段是读/写的,这就是为什么我们向它写入变量。然而,内存中的data段是不可执行的,所以我们向它写入的任何代码都不能执行。这种分离是内存保护的一部分,用于减轻缓冲区溢出和其他类型的二进制利用。
提示:我们可以使用分号;向汇编代码添加注释。我们可以使用注释来解释代码的每一部分的用途,以及每一行的作用。这样做可以为我们节省保存大量的时间,如果我们将来重新访问代码并需要理解它的话。
有了这个,我们应该了解程序集文件的基本结构。
Assembling & Disassembling
现在我们了解了Assembly文件的基本结构和元素,我们可以开始使用nasm工具组装它。我们在上一节中学习的整个程序集文件结构都是基于nasm文件结构的。在使用nasm组装我们的代码时,它理解文件的各个部分,然后正确地组装它们,以便在运行时正确运行。
在我们使用nasm组装代码之后,我们可以使用ld链接它以利用各种操作系统功能和库。
Assembling
首先,我们将上述代码复制到名为helloWorld.s的文件中。
注意:汇编文件通常使用.s或.asm扩展名。我们将在本模块中使用.s。
我们不必一直使用制表符来分隔汇编文件的各个部分,因为这只是出于演示目的。我们可以将以下代码写入我们的helloWorld.s文件:
Code:
global _start |
请注意,我们如何使用equ来动态计算message的长度,而不是使用静态的18。这将在以后变得非常方便。一旦我们这样做,我们将使用nasm组装文件,使用以下命令:
mikannse7@htb[/htb]$ nasm -f elf64 helloWorld.s |
注意:-f elf64标志用于说明我们想要汇编64位汇编代码。如果我们想汇编一个32位代码,我们会使用-f elf。
这应该输出一个helloWorld.o目标文件,然后将其组装成机器码,沿着所有变量和部分的详细信息。这个文件还不能执行。
Linking
最后一步是使用ld链接我们的文件。helloWorld.o目标文件虽然已组装,但仍然无法执行。这是因为nasm使用的许多引用和标签需要解析为实际地址,同时沿着将文件与可能需要的各种OS库链接。
这就是为什么Linux二进制文件被称为ELF,它代表Executable and Linkable Format。要使用ld链接文件,我们可以使用以下命令:
mikannse7@htb[/htb]$ ld -o helloWorld helloWorld.o |
注意:如果我们要汇编一个32位的二进制文件,我们需要添加’-m elf_i386‘标志。
一旦我们用ld链接文件,我们就应该有最终的可执行文件:
mikannse7@htb[/htb]$ ./helloWorld |
我们已经成功地组装和链接了我们的第一个组装文件。我们将通过这个模块频繁地组装、链接和运行我们的代码,所以让我们构建一个简单的bash脚本来使其更容易:
Code:
|
现在,我们可以将此脚本写入assembler.sh,chmod +x it,然后在我们的汇编文件中运行它。它将组装它,链接它,并运行它:
mikannse7@htb[/htb]$ ./assembler.sh helloWorld.s |
太好了!在我们继续之前,让我们分解并检查我们的文件,以了解更多关于我们刚刚完成的过程的信息。
Disassembling
要反汇编文件,我们将使用objdump工具,它从文件中转储机器代码并解释每个十六进制代码的汇编指令。我们可以使用-D标志反汇编一个二进制文件。
注意:我们还将使用标记-M intel,以便objdump将以我们正在使用的Intel语法编写指令,正如我们之前讨论的那样。
让我们从反汇编最终的ELF可执行文件开始:
mikannse7@htb[/htb]$ objdump -M intel -d helloWorld |
我们看到,我们的原始汇编代码被高度保留,唯一的变化是使用0x402000代替message变量,并将length常量替换为其值0x12。我们还看到,nasm有效地将我们的64-bit寄存器更改为32-bit子寄存器,以便尽可能使用更少的内存,就像将mov rax, 1更改为mov eax,0x1一样。
如果我们只想显示汇编代码,而不显示机器码或地址,我们可以添加--no-show-raw-insn --no-addresses标志,如下所示:
mikannse7@htb[/htb]$ objdump -M intel --no-show-raw-insn --no-addresses -d helloWorld |
注:注意objdump已将第三条指令更改为movabs。这与mov相同,所以如果需要重新汇编代码,可以将其更改回mov。
-d标志只会反汇编代码的.text部分。要转储任何字符串,我们可以使用-s标志,并添加-j .data以仅检查.data部分。这意味着我们也不需要添加-M intel。最后一个命令如下:
mikannse7@htb[/htb]$ objdump -sj .data helloWorld |
正如我们所看到的,.data部分确实包含了带有字符串message的Hello HTB Academy!变量。这应该会让我们给予一个更好的概念,即我们的代码是如何组装成机器码的,以及组装后的外观如何。接下来,让我们了解一下代码调试的基础知识,这是我们需要学习的一项关键技能。
GNU Debugger (GDB)
对于开发人员和pentester来说,这是一个需要学习的重要技能。搜索是用于查找和删除问题的术语(即,我们的代码中的bug,因此命名为debugging。当我们开发一个程序时,我们经常会在代码中遇到bug。不断地修改代码直到代码达到我们的期望是没有效率的。相反,我们通过设置断点来执行调试,并查看程序如何在每个断点上运行,以及我们的输入如何在它们之间变化,这应该让我们给予一个清晰的概念,是什么导致了bug。
用高级语言编写的程序可以在特定行上设置断点,并通过调试器运行程序以监视它们的行为。使用汇编,我们处理以汇编指令表示的机器代码,因此我们的断点设置在加载机器代码的内存位置,正如我们将看到的。
为了调试我们的二进制文件,我们将使用一个著名的用于Linux程序的调试器,称为GNU调试器(GDB)。Linux上还有其他类似的调试器,如Radare和Hopper,Windows上也有类似的调试器,如Immunity Debugger和WinGDB。也有强大的调试器可用于许多平台,如IDA Pro和EDB。在本模块中,我们将使用GDB。对于Linux二进制文件来说,它是最可靠的,因为它是由GNU直接构建和维护的,这使它与Linux系统及其组件有了很好的集成。
Installation
GDB安装在许多Linux发行版中,它也默认安装在Parrot OS和PwnBox中。如果您的VM中没有安装它,您可以使用apt通过以下命令安装它:
mikannse7@htb[/htb]$ sudo apt-get update |
GDB的一个重要特性是它支持第三方插件。GEF是一个很好的插件,它维护得很好,并且有很好的文档。GEF是一个免费的开源GDB插件,专为逆向工程和二进制开发而构建。这一事实使它成为一个很好的学习工具。
要将GEF添加到GDB,我们可以使用以下命令:
mikannse7@htb[/htb]$ wget -O ~/.gdbinit-gef.py -q https://gef.blah.cat/py |
入门
现在我们已经安装了这两个工具,我们可以使用以下命令运行gdb来调试我们的HelloWorld二进制文件,GEF将自动加载:
mikannse7@htb[/htb]$ gdb -q ./helloWorld |
正如我们在gef➤中看到的,GEF是在GDB运行时加载的。如果您在使用GEF时遇到任何问题,可以参考GEF文档,您可能会找到解决方案。
接下来,我们将经常组装和链接我们的汇编代码,然后用gdb运行它。为了快速完成,我们可以使用我们在上一节中编写的带有assembler.sh标志的-g脚本。它将组装并链接代码,然后使用gdb运行它,如下所示:
mikannse7@htb[/htb]$ ./assembler.sh helloWorld.s -g |
信息
一旦启动GDB,我们就可以使用info命令来查看程序的一般信息,比如它的函数或变量。
提示:如果我们想了解任何命令如何在GDB中运行,我们可以使用help CMD命令来获取其文档。例如,我们可以尝试执行help info
功能
首先,我们将使用info命令来检查二进制文件中定义了哪些functions:
gef➤ info functions |
正如我们所看到的,我们找到了主要的_start函数。
Variables
我们也可以使用info variables命令来查看程序中所有可用的变量:
gef➤ info variables |
正如我们所看到的,我们找到了message,沿着和其他一些定义内存段的默认变量。我们可以用函数做很多事情,但我们将重点关注两个要点:断点和断点。
Disassemble
要查看特定函数中的指令,我们可以使用disassemble或disas命令沿着函数名,如下所示:
gef➤ disas _start |
正如我们所看到的,我们得到的输出非常类似于我们的汇编代码和我们在上一节中从objdump得到的反汇编输出。我们需要关注这个反汇编的主要内容:每个指令和操作数的内存地址(即,参数)。
Having the memory address is critical for examining the variables/operands and setting breakpoints for a certain instruction. |
通过调试,您可能会注意到有些内存地址是0x00000000004xxxxx的形式,而不是它们在内存0xffffffffaa8a25ff中的原始地址。这是由于位置无关可执行程序$rip-relative addressing中的PIE,其中存储器地址是相对于它们与程序自己的虚拟RAM内的指令指针$rip的距离来使用的,而不是使用原始存储器地址。可以禁用此功能以降低二进制攻击的风险。
接下来,让我们通过使用断点、检查数据和单步执行程序来了解使用GDB进行调试的基本知识。
Debugging with GDB
现在我们有了关于程序的一般信息,我们将开始运行它并调试它。调试主要包括四个步骤:
| Step | Description |
|---|---|
Break |
在不同的兴趣点设置断点 |
Examine |
运行程序并在这些点上检查程序的状态 |
Step |
浏览程序,检查它如何处理每条指令和用户输入 |
Modify |
在特定的断点处修改特定寄存器或地址中的值,以研究它将如何影响执行 |
在本节中,我们将通过这些要点来学习使用GDB调试程序的基础知识。
Break
调试的第一步是设置breakpoints以在特定位置或满足特定条件时停止执行。这有助于我们检查程序的状态和寄存器的值。Breakpoints还允许我们在该点停止程序的执行,以便我们可以进入每个指令并检查它如何更改程序和值。
我们可以在特定地址或特定函数设置断点。要设置断点,我们可以使用break或b命令,沿着我们想要中断的地址或函数名。例如,为了遵循我们程序运行的所有指令,让我们在_start函数处中断,如下所示:
gef➤ b _start |
现在,为了启动我们的程序,我们可以使用run或r命令:
gef➤ b _start |
如果我们想在某个地址设置断点,比如_start+10,我们可以选择b *_start+10或b *0x40100a:
gef➤ b *0x40100a |
*告诉GDB在存储在0x40100a中的指令处中断。
注意:一旦程序运行,如果我们设置了另一个断点,比如b *0x401005,为了继续到那个断点,我们应该使用continue或c命令。如果我们再次使用run或r,它将从头开始运行程序。这对于跳过循环很有用,我们将在本模块的后面部分看到。
如果我们想查看在执行的任何时候有哪些断点,可以使用info breakpoint命令。我们也可以disable、enable或delete任何断点。此外,GDB还支持设置条件中断,当满足特定条件时停止执行。
Examine
调试的下一步是examining寄存器和地址中的值。正如我们在前面的终端输出中看到的,当我们遇到断点时,GEF自动为我们提供了很多有用的信息。这是使用GEF插件的好处之一,因为它可以自动执行我们通常在每个断点处执行的许多步骤,例如检查寄存器,堆栈和当前汇编指令。
要手动检查任何地址或寄存器或检查任何其他地址或寄存器,我们可以使用格式为x的x/FMT ADDRESS命令,如help x所示。ADDRESS是我们要检查的地址或寄存器,而FMT是检查格式。检查格式FMT可以有三个部分:
| Argument | Description | Example |
|---|---|---|
Count Break |
我们要重复检查的次数 | 2, 3, 10 2、3、10 |
Format Break |
我们希望结果表示的格式 | x(hex), s(string), i(instruction) x(hex)、s(string)、i(instruction) |
Size Break |
我们要检查的内存大小 | b(byte), h(halfword), w(word), g(giant, 8 bytes) b(byte)、h(halfword)、w(word)、g(giant, 8 bytes) |
Instructions
例如,如果我们想检查行中接下来的四条指令,我们将不得不检查$rip寄存器(它保存下一条指令的地址),并使用4作为count,i作为format,g作为size(对于8字节或64位)。因此,最后的检查命令将是x/4ig $rip,如下所示:
gef➤ x/4ig $rip |
我们看到,我们得到了以下四个预期的指令。这可以帮助我们通过程序检查某些区域以及它们可能包含的指令。
Strings
我们还可以检查存储在特定内存地址的变量。从前面的反汇编中,我们知道我们的message变量存储在地址.data上的0x402000部分。我们还看到了即将到来的命令movabs rsi, 0x402000,所以我们可能想检查从0x402000移动了什么。
在这种情况下,我们不会为Count放置任何东西,因为我们只需要一个地址(1是默认值),并且将使用s作为格式以字符串格式而不是十六进制格式获取它:
gef➤ x/s 0x402000 |
正如我们所看到的,我们可以看到这个地址处的字符串表示为文本而不是十六进制字符。
注意:如果我们没有指定Size或Format,它将默认为我们使用的最后一个。
Addresses
最常见的检查格式是十六进制x。我们经常需要检查包含十六进制数据的地址和寄存器,例如内存地址,指令或二进制数据。让我们来看看前面同样的指令,但格式是hex,看看它是什么样子:
gef➤ x/wx 0x401000 |
我们看到的不是mov eax,0x1,而是0x000001b8,这是mov eax,0x1机器码的十六进制表示,采用little-endian格式。
- 这是读作:
b8 01 00 00。
尝试重复我们使用x检查字符串的命令来检查十六进制的字符串。我们应该看到相同的文本,但在十六进制格式。我们还可以使用GEF功能来检查某些地址。例如,在任何时候,我们都可以使用registers命令打印出所有寄存器的当前值:
gef➤ registers |
Step
调试的第三步是stepping,每次通过程序一条指令或一行代码。正如我们所看到的,我们目前正在执行helloWorld程序中的第一条指令:
─────────────────────────────────────────────────────────────────────────────────── code:x86:64 ──── |
注意:带有->符号的指令是我们所处的位置,它尚未被处理。
要浏览程序,我们可以使用三个不同的命令:用途:stepi和step。
Step Instruction
stepi或si命令将逐个执行汇编指令,这是调试时可能执行的最小级别的步骤。让我们使用s命令来看看我们如何进入下一条指令:
─────────────────────────────────────────────────────────────────────────────────── code:x86:64 ──── |
正如我们所看到的,我们只执行了一步,然后在mov edi, 0x1指令处再次停止。
Step Count
与检查类似,我们可以通过在si命令后面添加一个数字来重复该命令。例如,如果我们想移动3步到达syscall指令,我们可以这样做:
gef➤ si 3 |
正如我们所看到的,我们按预期在syscall指令处停止。
提示:您可以点击return/enter空,以重复最后一个命令。尝试在这个阶段击中它,你应该再做3个步骤,并在另一个syscall指令处中断。
Step 步骤
另一方面,step或s命令将继续执行,直到到达下一行代码或从当前函数中退出。如果我们运行一个汇编代码,它将在我们退出当前函数_start时中断。
如果在这个函数中有对另一个函数的调用,它将在该函数的开始处中断。否则,它将在程序结束后退出此函数后中断。让我们尝试使用s,看看会发生什么:
gef➤ step |
我们看到,执行一直持续到我们到达_start函数的出口,所以我们到达了程序的结尾和exited normally,没有任何错误。我们还看到GDB也打印了程序的输出Hello HTB Academy!。
注意:还有next或n命令,它们也将继续到下一行,但会跳过同一行代码中调用的任何函数,而不是像step那样中断它们。还有nexti或ni,类似于si,但跳过函数调用,我们将在模块中稍后看到。
Modify 修改
调试的最后一步是在某个执行点上寄存器和地址中的modifying值。这有助于我们看到这将如何影响程序的执行。
Addresses
要修改GDB中的值,我们可以使用set命令。但是,我们将在patch中使用GEF命令来简化这一步。我们在GDB中输入help patch,以获得其帮助菜单:
gef➤ help patch |
正如我们所看到的,我们必须提供新值的type/size,要存储的location和我们想要使用的value。因此,让我们尝试将存储在.data部分中的字符串(如前所述,地址为0x402000)更改为字符串Patched!\n。
我们将在第一个syscall在0x401019处中断,然后执行修补程序,如下所示:
gef➤ break *0x401019 |
我们看到我们成功地修改了字符串,得到了Patched!\n Academy!而不是旧的字符串。注意我们如何使用\x0a在字符串后面添加一个新行。
Registers
我们还注意到我们没有替换整个字符串。这是因为我们只修改了字符串的长度,而保留了旧字符串的其余部分。最后,printf函数指定要打印的字节长度为0x12。
为了解决这个问题,让我们将存储在$rdx中的值修改为字符串的长度,即0x9。我们将只修补一个字节的大小。我们将在本模块的后面详细介绍syscall的工作原理。让我们演示如何使用set修改$rdx,如下所示:
gef➤ break *0x401019 |
我们可以看到,我们成功地修改了最终打印的字符串,并让程序输出了我们选择的内容。修改寄存器和地址值的能力将在调试和二进制开发中对我们有很大帮助,因为它允许我们测试各种值和条件,而不必每次都更改代码和重新编译二进制。
Conclusion
无论我们是想确切地了解程序失败的原因,还是想了解程序是如何运行的,以及它在每个点上都在做什么,GDB都变得非常方便。
对于渗透测试,这个过程使我们能够了解程序在某个点上如何处理输入,以及它失败的确切原因。这使我们能够开发利用这些失败的漏洞,正如我们将在二进制开发模块中学习的那样。