
Web RequestsHTB
HTTP Fundamentals
HyperText Transfer Protocol (HTTP)
今天,我们使用的大多数应用程序都不断与互联网交互,包括Web和移动的应用程序。大多数互联网通信都是通过HTTP协议进行的Web请求。HTTP是用于访问万维网资源的应用程序级协议。术语hypertext代表包含指向其他资源的链接的文本和读者可以轻松解释的文本。
HTTP通信由客户端和服务器组成,其中客户端向服务器请求资源。服务器处理请求并返回请求的资源。HTTP通信的默认端口是端口80,但根据Web服务器配置,可以将其更改为任何其他端口。当我们使用互联网访问不同的网站时,也会使用相同的请求。我们输入Fully Qualified Domain Name(FQDN)作为Uniform Resource Locator(URL)以访问所需的网站,如www.hackthebox.com。
URL
HTTP上的资源是通过URL访问的,它提供了比简单地指定我们想要访问的网站更多的规范。让我们来看看URL的结构: 
以下是每个组件所代表的内容:
| Component | Example | Description |
|---|---|---|
Scheme |
http:// https:// |
这用于标识客户端正在访问的协议,并以冒号和双斜杠(://)结束。 |
User Info Scheme |
admin:password@ Scheme |
这是一个可选组件,包含用于向主机进行身份验证的凭据(以冒号:分隔),并使用at符号(@)与主机分隔 |
Host Scheme |
inlanefreight.com Scheme |
主机表示资源位置。这可以是主机名或IP地址 |
Port Scheme |
:80 Scheme |
Port和Host之间用冒号(:)隔开。如果未指定端口,则http方案默认为端口80,https方案默认为端口443 |
Path Scheme |
/dashboard.php Scheme |
这指向正在访问的资源,可以是文件或文件夹。如果没有指定路径,服务器返回默认索引(例如index.html)。 |
Query String Scheme |
?login=true Scheme |
查询字符串以问号(?)开头,由参数(例如login)和值(例如true)组成。多个参数可以用&符号(&)分隔。 |
Fragments Scheme |
#status Scheme |
片段由客户端的浏览器处理,以定位主要资源中的部分(例如,页面上的标题或部分)。 |
并非所有组件都需要访问资源。主要的必填字段是scheme和host,如果没有它们,请求将没有资源可供请求。
HTTP Flow

上图从很高的层次上展示了HTTP请求的剖析。用户第一次在浏览器中输入URL(inlanefreight.com)时,它会向DNS(域名解析)服务器发送一个请求,以解析域并获取其IP。DNS服务器查找inlanefreight.com的IP地址并返回。所有域名都需要以这种方式解析,因为没有IP地址,服务器无法通信。
注意:我们的浏览器通常首先在本地’/etc/hosts‘文件中查找记录,如果所请求的域不存在于其中,那么他们将联系其他DNS服务器。我们可以使用’/etc/hosts‘手动添加记录到DNS解析,通过添加IP后跟域名。
一旦浏览器获得链接到请求域的IP地址,它会向默认HTTP端口(例如80)发送GET请求,请求根/路径。然后,Web服务器接收请求并处理它。默认情况下,服务器配置为在接收到针对/的请求时返回索引文件。
在这种情况下,index.html的内容被Web服务器读取并作为HTTP响应返回。响应还包含状态代码(例如200 OK),表示请求已成功处理。然后,web浏览器呈现index.html内容并将其呈现给用户。
注意:本模块主要关注HTTP Web请求。有关HTML和Web应用程序的更多信息,请参阅Web应用程序简介模块。
cURL
在本模块中,我们将通过任何Web渗透测试人员最重要的两个工具发送Web请求,一个是Web浏览器,如Chrome或Firefox,另一个是cURL命令行工具。
cURL(客户端URL)是一个命令行工具和库,主要支持HTTP沿着许多其他协议。这使得它成为脚本和自动化的良好候选者,对于从命令行发送各种类型的Web请求至关重要,这对于许多类型的Web渗透测试都是必要的。
我们可以将一个基本的HTTP请求作为cURL的参数发送到任何URL,如下所示:
mikannse7@htb[/htb]$ curl inlanefreight.com |
我们看到cURL不像Web浏览器那样呈现HTML/JavaScript/CSS代码,而是以原始格式打印。然而,作为渗透测试人员,我们主要对请求和响应上下文感兴趣,这通常比Web浏览器更快,更方便。
我们也可以使用cURL下载页面或文件,并使用-O标志将内容输出到文件中。如果我们想指定输出文件名,我们可以使用-o标志并指定名称。否则,我们可以使用-O,cURL将使用远程文件名,如下所示:
mikannse7@htb[/htb]$ curl -O inlanefreight.com/index.html |
正如我们所看到的,这次输出没有打印出来,而是保存到了index.html中。我们注意到cURL在处理请求时仍然打印一些状态。我们可以使用-s标志使状态静默,如下所示:
mikannse7@htb[/htb]$ curl -s -O inlanefreight.com/index.html |
这一次,cURL没有打印任何东西,因为输出被保存到index.html文件中。最后,我们可以使用-h标志来查看我们可以使用cURL的其他选项:
mikannse7@htb[/htb]$ curl -h |
正如上面的消息所提到的,我们可以使用--help all打印更详细的帮助菜单,或者使用--help category(例如-h http)打印特定标志的详细帮助。如果我们需要阅读更详细的文档,我们可以使用man curl来查看完整的cURL手册页面。
在接下来的部分中,我们将介绍上述大多数标志,并查看我们应该在哪里使用它们。
Hypertext Transfer Protocol Secure (HTTPS)
在上一节中,我们讨论了如何发送和处理HTTP请求。然而,HTTP的一个显著缺点是所有数据都以明文传输。这意味着源和目标之间的任何人都可以执行中间人(MiTM)攻击来查看传输的数据。
为了解决这一问题,人们发明了HTTPS(HTTP Secure)协议,所有通信都以加密格式传输,因此即使第三方拦截了请求,也无法从中提取数据。因此,HTTPS已成为互联网上网站的主流方案,HTTP正在逐步淘汰,很快大多数Web浏览器将不允许访问HTTP网站。
HTTPS Overview
如果我们检查一个HTTP请求,我们可以看到在Web浏览器和Web应用程序之间不强制执行安全通信的效果。例如,以下是HTTP登录请求的内容: 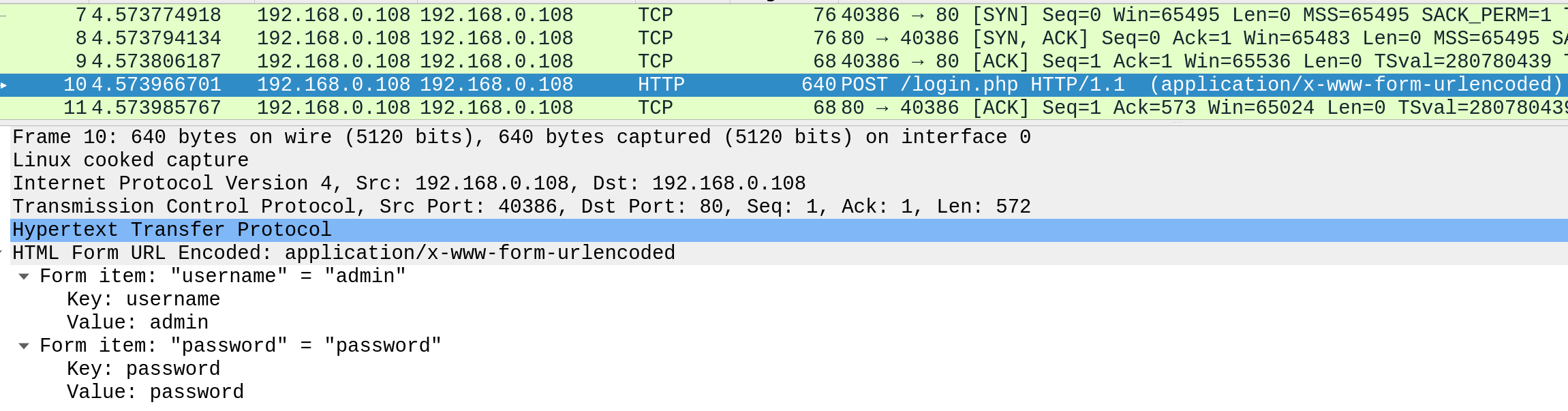
我们可以看到登录凭证可以以明文形式查看。这将使同一网络(如公共无线网络)上的人很容易捕获请求并将凭据重新用于恶意目的。
相反,当有人拦截并分析来自HTTPS请求的流量时,他们会看到如下内容: 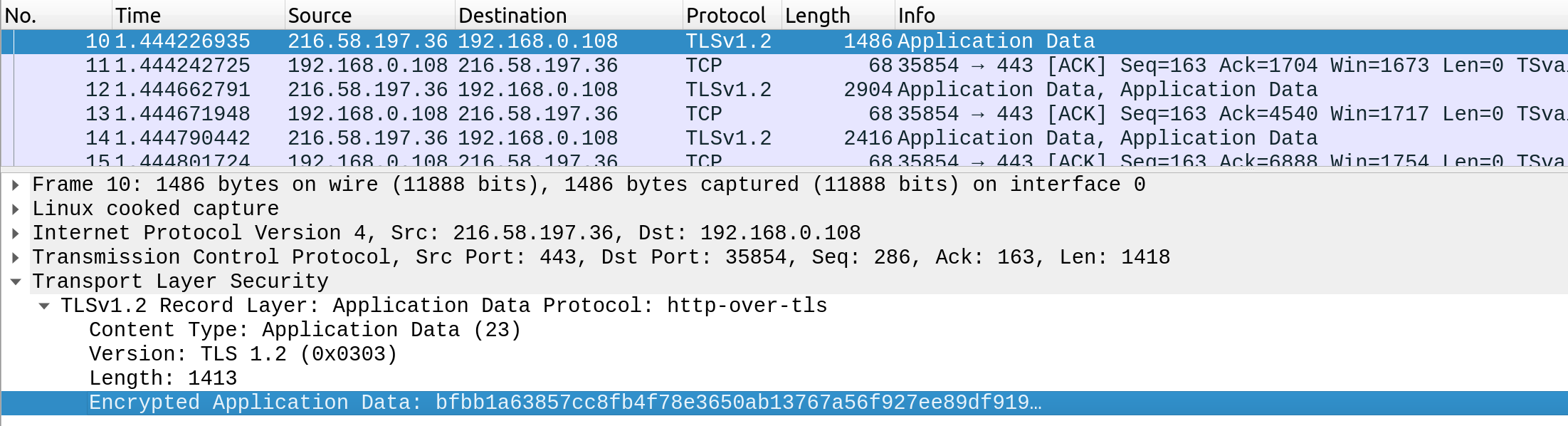
正如我们所看到的,数据是作为单个加密流传输的,这使得任何人都很难捕获凭据或任何其他敏感数据等信息。
可以通过URL中的https://(例如https://www.google.com)以及Web浏览器地址栏中的锁图标(位于URL左侧)来识别强制使用HTTPS的网站: 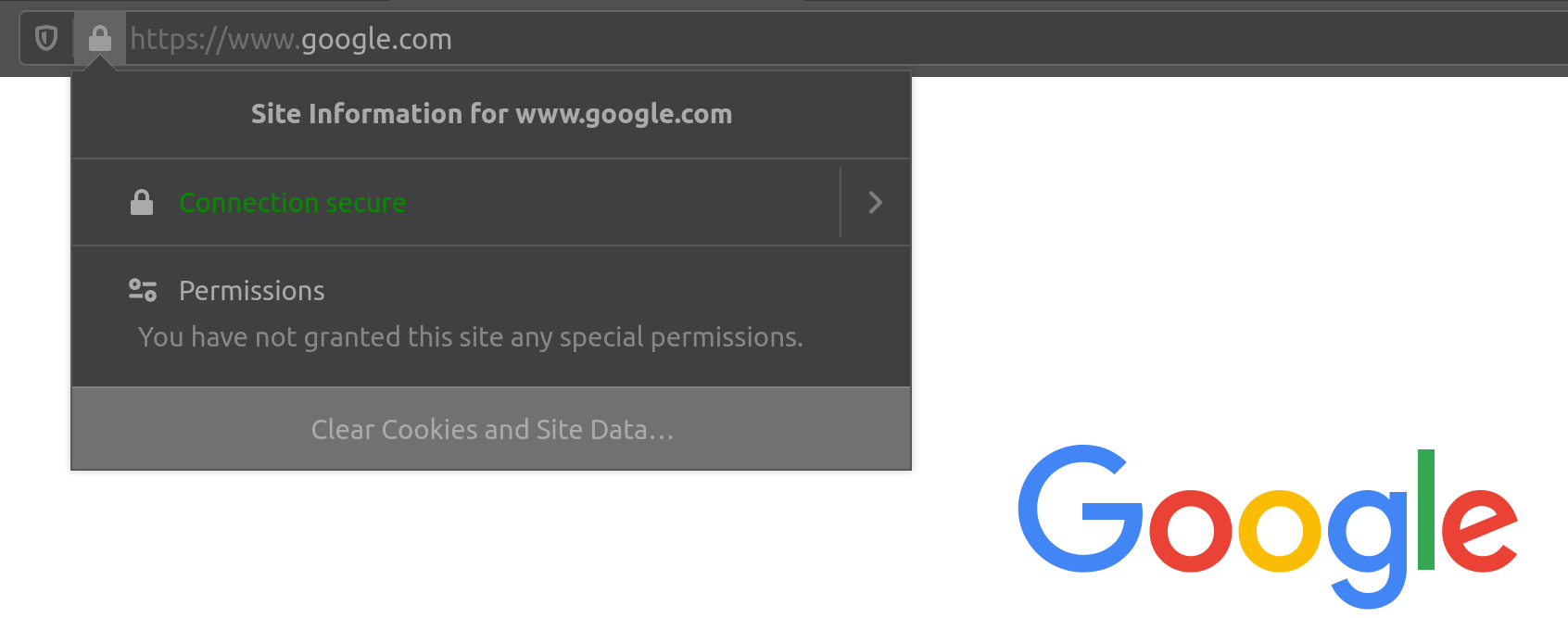
因此,如果我们访问使用HTTPS的网站,如Google,所有流量都将被加密。
注意:虽然通过HTTPS协议传输的数据可能会被加密,但如果请求与明文DNS服务器联系,则仍然可能会显示访问的URL。因此,建议使用加密的DNS服务器(例如8.8.8.8或1.1.1.1),或使用VPN服务,以确保所有流量都得到正确加密。
HTTPS Flow
让我们来看看HTTPS是如何在高级别上运行的: 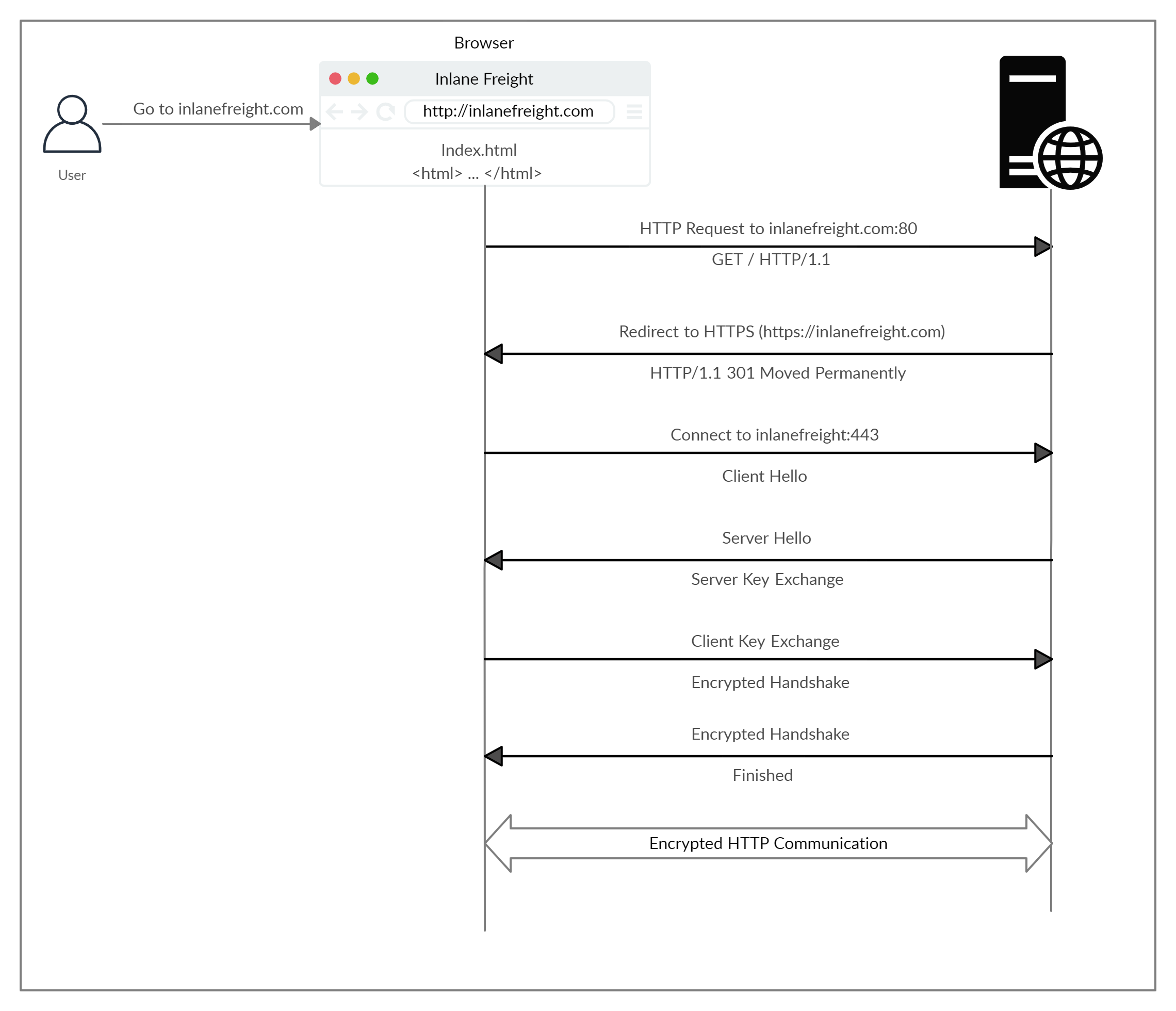
如果我们键入http://而不是https://来访问强制HTTPS的网站,浏览器会尝试解析域并将用户重定向到托管目标网站的Web服务器。请求首先发送到端口80,这是未加密的HTTP协议。服务器检测到这一点,并将客户端重定向到安全的HTTPS端口443。这是通过301 Moved Permanently响应代码完成的,我们将在下一节中讨论。
接下来,客户端(Web浏览器)发送一个“客户端问候”数据包,给出有关其自身的信息。在此之后,服务器回复“server hello”,然后进行密钥交换以交换SSL证书。客户端验证密钥/证书并发送自己的密钥/证书。在此之后,启动加密握手以确认加密和传输是否正常工作。
一旦握手成功完成,正常的HTTP通信将继续进行,然后进行加密。这是密钥交换的一个非常高层次的概述,超出了本模块的范围。
注意:根据具体情况,攻击者可能能够执行HTTP降级攻击,将HTTPS通信降级为HTTP,使数据以明文传输。这是通过设置一个中间人(MITM)代理来完成的,以在用户不知情的情况下通过攻击者的主机传输所有流量。但是,大多数现代浏览器、服务器和Web应用程序都可以抵御这种攻击。
cURL for HTTPS
cURL应该自动处理所有HTTPS通信标准,并执行安全握手,然后自动加密和解密数据。但是,如果我们使用无效的SSL证书或过期的SSL证书联系网站,那么cURL默认情况下不会继续进行通信,以防止前面提到的MITM攻击:
mikannse7@htb[/htb]$ curl https://inlanefreight.com |
现代的Web浏览器也会这样做,警告用户不要访问具有无效SSL证书的网站。
我们在测试本地Web应用程序或出于实践目的托管的Web应用程序时可能会遇到这样的问题,因为这些Web应用程序可能尚未实现有效的SSL证书。要跳过cURL的证书检查,我们可以使用-k标志:
mikannse7@htb[/htb]$ curl -k https://inlanefreight.com |
正如我们所看到的,这次请求通过了,我们收到了响应数据。
HTTP Headers
我们已经在上一节中看到了HTTP请求和响应头的示例。这样的HTTP头在客户端和服务器之间传递信息。有些头只与请求或响应一起使用,而其他一些通用头对两者都是通用的。
标头可以有一个或多个值,附加在标头名称之后,并用冒号分隔。我们可以将标题分为以下几类:
General HeadersEntity HeadersRequest HeadersResponse HeadersSecurity Headers
让我们来讨论这些类别。
General Headers
通用头在HTTP请求和响应中都使用。它们是上下文相关的,用于describe the message rather than its contents。
| Header | Example | Description |
|---|---|---|
Date |
Date: Wed, 16 Feb 2022 10:38:44 GMT |
保存消息发出的日期和时间。最好将时间转换为标准UTC时区。 |
Connection |
Connection: close |
指示当前网络连接在请求完成后是否应保持活动状态。此头文件的两个常用值是close和keep-alive。来自客户端或服务器的close值意味着他们想要终止连接,而keep-alive头表示连接应该保持打开以接收更多数据和输入。 |
Entity Headers
与一般头类似,实体头可以是common to both the request and response。这些头用于消息传输的describe the content(实体)。它们通常出现在响应和POST或PUT请求中。
| Header | Example | Description |
|---|---|---|
Content-Type Connection |
Content-Type: text/html Connection |
用于描述正在转移的资源类型。该值由客户端的浏览器自动添加,并在服务器响应中返回。charset字段表示编码标准,例如UTF-8。 |
Media-Type Connection |
Media-Type: application/pdf Connection |
media-type类似于Content-Type,描述正在传输的数据。这个头在让服务器解释我们的输入时起着至关重要的作用。charset字段也可以与该报头一起使用。 |
Boundary Connection |
boundary="b4e4fbd93540" Connection |
当同一邮件中有多个内容时,用作分隔内容的标记。例如,在表单数据中,此边界用作--b4e4fbd93540来分隔表单的不同部分。 |
Content-Length Connection |
Content-Length: 385 Connection |
保存被传递的实体的大小。这个头是必要的,因为服务器使用它从消息体读取数据,并且由浏览器和cURL等工具自动生成。 |
Content-Encoding Connection |
Content-Encoding: gzip Connection |
数据在被传递之前可以经历多次转换。例如,可以压缩大量数据以减小消息大小。应该使用Content-Encoding头指定所使用的编码类型。 |
Request Headers
客户端在HTTP事务中发送请求头。这些头是消息的used in an HTTP request and do not relate to the content。以下是常见于HTTP请求中的头。
| Header | Example | Description |
|---|---|---|
Host Connection |
Host: www.inlanefreight.com `Connection |
用于指定要查询资源的主机。它可以是域名或IP地址。HTTP服务器可以配置为托管不同的网站,这些网站是基于主机名显示的。这使得主机头成为一个重要的枚举目标,因为它可以指示目标服务器上是否存在其他主机。 |
User-Agent Connection |
User-Agent: curl/7.77.0 Connection |
User-Agent头用于描述请求资源的客户端。这个头可以透露很多关于客户端的信息,比如浏览器、版本和操作系统。 |
Referer Connection |
Referer: http://www.inlanefreight.com/ Connection |
表示当前请求来自何处。例如,单击Google搜索结果中的链接将使https://google.com成为引用者。信任这个头可能是危险的,因为它很容易被操纵,导致意想不到的后果。 |
Accept Connection |
Accept: */* Connection |
Accept头描述了客户端可以理解的媒体类型。它可以包含多个媒体类型,由逗号分隔。*/*值表示接受所有媒体类型。 |
Cookie Connection |
Cookie: PHPSESSID=b4e4fbd93540 Connection |
包含格式为name=value的cookie值对。Cookie是存储在客户端和服务器上的一段数据,用作标识符。每个请求都将这些传递给服务器,从而维护客户端的访问。Cookie还可以用于其他目的,例如保存用户偏好或会话跟踪。在一个标头中可以有多个cookie,并由分号分隔。 |
Authorization Connection |
Authorization: BASIC cGFzc3dvcmQK Connection |
服务器识别客户端的另一种方法。成功验证后,服务器返回客户端唯一的令牌。与cookie不同,令牌仅存储在客户端,并由服务器根据请求检索。根据所使用的Web服务器和应用程序类型,有多种身份验证类型。 |
完整的请求头列表及其用法可以在这里找到。
Response Headers
响应头可以是used in an HTTP response and do not relate to the content。某些响应头(如Age、Location和Server)用于提供有关响应的更多上下文。下面的头通常出现在HTTP响应中。
| Header | Example例如 | Description描述 |
|---|---|---|
Server Connection |
Server: Apache/2.2.14 (Win32) Connection |
包含有关处理请求的HTTP服务器的信息。它可用于获取有关服务器的信息(如版本),并进一步枚举它。 |
Set-Cookie Connection |
Set-Cookie: PHPSESSID=b4e4fbd93540 Connection |
包含客户身份识别所需的Cookie。浏览器解析cookie并存储它们以备将来的请求。这个头与Cookie请求头的格式相同。 |
WWW-Authenticate Connection |
WWW-Authenticate: BASIC realm="localhost" Connection |
通知客户端访问请求的资源所需的身份验证类型。 |
Security Headers
最后,我们有安全头。随着各种浏览器和基于Web的攻击的增加,定义某些增强安全性的标头是必要的。HTTP安全标头是浏览器在访问网站时要遵循的a class of response headers used to specify certain rules and policies。
| Header | Example | Description |
|---|---|---|
Content-Security-Policy Connection |
Content-Security-Policy: script-src 'self' Connection |
规定网站对外部注入资源的政策。这可以是JavaScript代码以及脚本资源。此标头指示浏览器仅接受来自某些受信任域的资源,从而防止跨站点脚本(XSS)等攻击。 |
Strict-Transport-Security Connection |
Strict-Transport-Security: max-age=31536000 Connection |
阻止浏览器通过明文HTTP协议访问网站,并强制所有通信都通过安全HTTPS协议进行。这可以防止攻击者嗅探Web流量并访问受保护的信息,如密码或其他敏感数据。 |
Referrer-Policy Connection |
Referrer-Policy: origin Connection |
指示浏览器是否应包含通过Referer头指定的值。它可以帮助避免在浏览网站时泄露敏感的URL和信息。 |
注意:本节只提到常见HTTP头的一小部分。还有许多其他上下文标头可以在HTTP通信中使用。应用程序也可以根据自己的需求定义自定义头。标准HTTP头的完整列表可以在这里找到。
cURL
在上一节中,我们看到了如何在cURL中使用-v标志来显示HTTP请求和响应的完整细节。如果我们只想看到响应头,那么我们可以使用-I标志来发送HEAD请求,只显示响应头。此外,我们可以使用-i标志来显示标题和响应正文(例如HTML代码)。两者之间的区别在于-I发送一个HEAD请求(如下一节所示),而-i发送我们指定的任何请求并打印头。
以下命令显示了使用-I标志的示例输出:
mikannse7@htb[/htb]$ curl -I https://www.inlanefreight.com |
练习:试着浏览以上所有标题,看看你是否能回忆起它们的用法。
除了查看头部,cURL还允许我们使用-H标志设置请求头部,我们将在后面的部分中看到。一些头文件,如User-Agent或Cookie头文件,有自己的标志。例如,我们可以使用-A来设置我们的User-Agent,如下所示:
mikannse7@htb[/htb]$ curl https://www.inlanefreight.com -A 'Mozilla/5.0' |
练习:尝试在上面的例子中使用-I或-v标志,以确保我们确实使用-A标志更改了我们的User-Agent。
Browser DevTools
最后,让我们看看如何使用浏览器devtools预览HTTP标头。正如我们在上一节中所做的那样,我们可以转到Network选项卡来查看页面发出的不同请求。我们可以点击任何请求查看其详细信息: 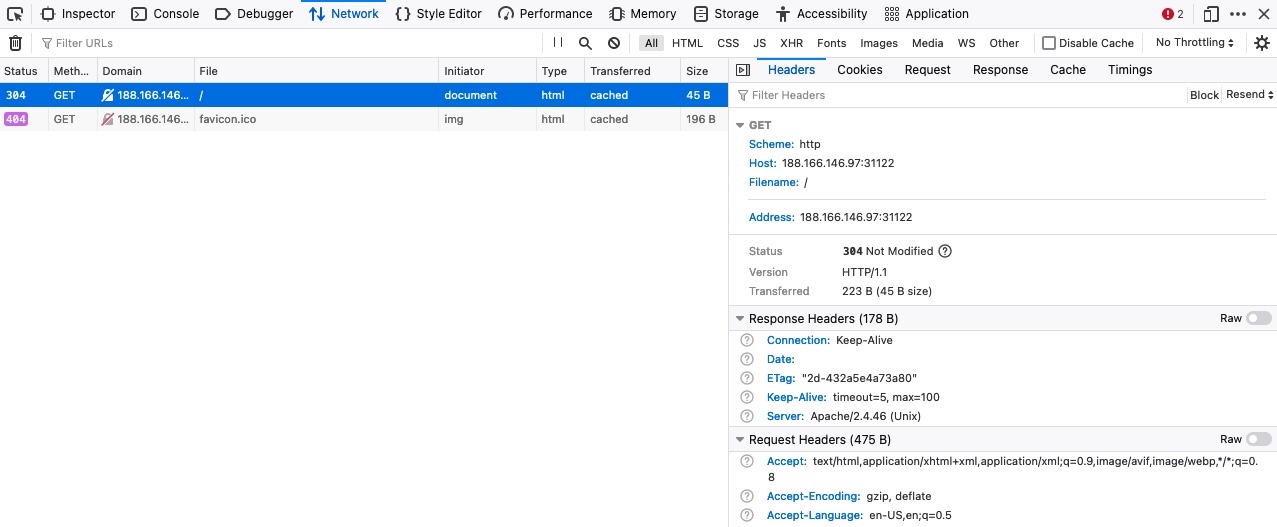
在第一个Headers选项卡中,我们可以看到HTTP请求和HTTP响应头。devtools会自动将标题排列成部分,但我们可以单击Raw按钮以原始格式查看它们的详细信息。此外,我们可以检查Cookies选项卡以查看请求使用的任何Cookie,如即将到来的部分所讨论的。
HTTP Methods
HTTP Methods and Codes
HTTP支持多种访问资源的方法。在HTTP协议中,有几种请求方法允许浏览器向服务器发送信息、表单或文件。这些方法用于告诉服务器如何处理我们发送的请求以及如何回复。
我们在前面的部分中测试了HTTP请求中使用的不同HTTP方法。对于cURL,如果我们使用-v预览完整的请求,第一行包含HTTP方法(例如GET / HTTP/1.1),而对于浏览器devtools,HTTP方法显示在Method列中。此外,响应头还包含HTTP响应代码,该代码说明了处理HTTP请求的状态。
Request Methods
以下是一些常用的方法:
| Method | Description |
|---|---|
GET |
请求特定资源。其他数据可以通过URL中的查询字符串(例如?param=value)传递到服务器。 |
POST |
将数据发送到服务器。它可以处理多种类型的输入,如文本、PDF和其他形式的二进制数据。该数据被附加在请求主体中的头之后。POST方法通常用于发送信息(例如表单/登录)或将数据上传到网站,例如图像或文档。 |
HEAD |
请求在向服务器发出GET请求时将返回的标头。它不返回请求体,通常在下载资源之前检查响应长度。 |
PUT |
.在服务器上创建新资源。在没有适当控制的情况下允许此方法可能会导致上传恶意资源。 |
DELETE |
在Web服务器上创建一个现有资源。如果没有正确保护,可能会删除Web服务器上的关键文件,从而导致拒绝服务(DoS)。 |
OPTIONS |
返回有关服务器的信息,例如服务器接受的方法。 |
PATCH |
拒绝对指定位置的资源进行部分修改。 |
该列表仅突出显示了一些最常用的HTTP方法。特定方法的可用性取决于服务器和应用程序配置。有关HTTP方法的完整列表,您可以访问此链接。
注意:大多数现代Web应用程序主要依赖于GET和POST方法。然而,任何使用REST API的Web应用程序也依赖于PUT和DELETE,它们分别用于更新和删除API端点上的数据。有关详细信息,请参阅Web应用程序简介模块。
Response Codes
HTTP状态码用于告诉客户端其请求的状态。HTTP服务器可以返回五种类型的响应代码:
| Type | Description |
|---|---|
1xx PUT |
提供信息,但不影响请求的处理。 |
2xx PUT |
当请求成功时返回。 |
3xx PUT |
当服务器重定向客户端时返回。 |
4xx PUT |
例如,请求不存在的资源或请求错误的格式。 |
5xx PUT |
本身有问题时返回。 |
以下是上述每个HTTP方法类型中常见的一些示例:
| Code | Description |
|---|---|
200 OK PUT |
在成功请求时返回,响应体通常包含所请求的资源。 |
302 Found PUT |
将客户端重定向到其他URL。例如,在成功登录后将用户重定向到其仪表板。 |
400 Bad Request PUT |
在遇到格式错误的请求(如缺少行终止符的请求)时返回。 |
403 Forbidden PUT |
表示客户端对资源没有适当的访问权限。当服务器检测到来自用户的恶意输入时,它也可以被返回。 |
404 Not Found PUT |
当客户端请求服务器上不存在的资源时返回。 |
500 Internal Server Error PUT |
当服务器无法处理请求时返回。 |
有关标准HTTP响应代码的完整列表,您可以访问此链接。除了标准的HTTP代码外,各种服务器和提供商(如Cloudflare或AWS)都实现了自己的代码。
GET
每当我们访问任何URL时,我们的浏览器都会默认使用GET请求来获取该URL上托管的远程资源。一旦浏览器接收到它请求的初始页面,它可能会使用各种HTTP方法发送其他请求。这可以通过浏览器devtools中的Network选项卡观察到,如前一节所示。
练习:选择您选择的任何网站,并在您访问时监视浏览器devtools中的Network选项卡,以了解页面正在执行的操作。这种技术可以用来彻底了解Web应用程序如何与其后端交互,这可能是任何Web应用程序评估或错误奖励练习的基本练习。
HTTP Basic Auth
当我们访问本节末尾的练习时,它会提示我们输入用户名和密码。与使用HTTP参数验证用户凭据(例如POST请求)的常见登录表单不同,这种类型的身份验证使用basic HTTP authentication,由Web服务器直接处理以保护特定页面/目录,而不直接与Web应用程序交互。
要访问该页面,我们必须输入一对有效的凭据,在本例中为admin:admin: 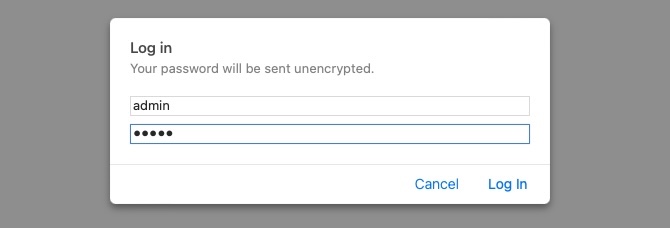
一旦我们输入凭据,我们就可以访问页面: 
让我们尝试使用cURL访问页面,我们将添加-i来查看响应头:
mikannse7@htb[/htb]$ curl -i http://<SERVER_IP>:<PORT>/ |
正如我们所看到的,我们在响应体中得到了Access denied,在Basic realm="Access denied"头中也得到了WWW-Authenticate,这证实了这个页面确实使用了basic HTTP auth,正如在Headers部分所讨论的那样。要通过cURL提供凭证,我们可以使用-u标志,如下所示:
mikannse7@htb[/htb]$ curl -u admin:admin http://<SERVER_IP>:<PORT>/ |
这一次我们在响应中得到了页面。还有另一种方法我们可以提供basic HTTP auth凭证,这是直接通过URL作为(username:password@URL),正如我们在第一节中讨论的那样。如果我们用cURL或浏览器尝试相同的操作,我们也可以访问页面:
mikannse7@htb[/htb]$ curl http://admin:admin@<SERVER_IP>:<PORT>/ |
我们也可以尝试在浏览器上访问相同的URL,并且我们也应该进行身份验证。
练习:尝试通过在上面的请求中添加-i来查看响应头,并查看经过身份验证的响应与未经身份验证的响应有何不同。
HTTP Authorization Header
如果我们在前面的cURL命令中添加-v标志:
mikannse7@htb[/htb]$ curl -v http://admin:admin@<SERVER_IP>:<PORT>/ |
当我们使用basic HTTP auth时,我们看到我们的HTTP请求将Authorization头设置为Basic YWRtaW46YWRtaW4=,这是admin:admin的base64编码值。如果我们使用现代的身份验证方法(例如JWT),则Authorization将属于Bearer类型,并且将包含更长的加密令牌。
让我们尝试手动设置Authorization,而不提供凭据,看看它是否允许我们访问页面。我们可以使用-H标志来设置头部,并将使用与上述HTTP请求相同的值。我们可以多次添加-H标志来指定多个头:
mikannse7@htb[/htb]$ curl -H 'Authorization: Basic YWRtaW46YWRtaW4=' http://<SERVER_IP>:<PORT>/ |
正如我们所看到的,这也给了我们访问页面的权限。这些是我们可以用来验证页面的一些方法。大多数现代Web应用程序使用后端脚本语言(例如PHP)构建的登录表单,这些脚本语言利用HTTP POST请求来验证用户,然后返回一个cookie来维护他们的身份验证。
GET Parameters
一旦我们通过身份验证,我们就可以访问City Search函数,在其中我们可以输入搜索词并获得匹配城市的列表:
当页面返回我们的结果时,它可能正在联系远程资源以获取信息,然后将它们显示在页面上。为了验证这一点,我们可以打开浏览器devtools并转到Network选项卡,或者使用快捷方式[CTRL+SHIFT+E]来转到同一选项卡。在我们输入搜索词并查看请求之前,我们可能需要单击左上角的trash图标,以确保我们清除任何以前的请求并仅监视新请求: 
之后,我们可以输入任何搜索词并点击回车,我们会立即注意到一个新的请求被发送到后端: 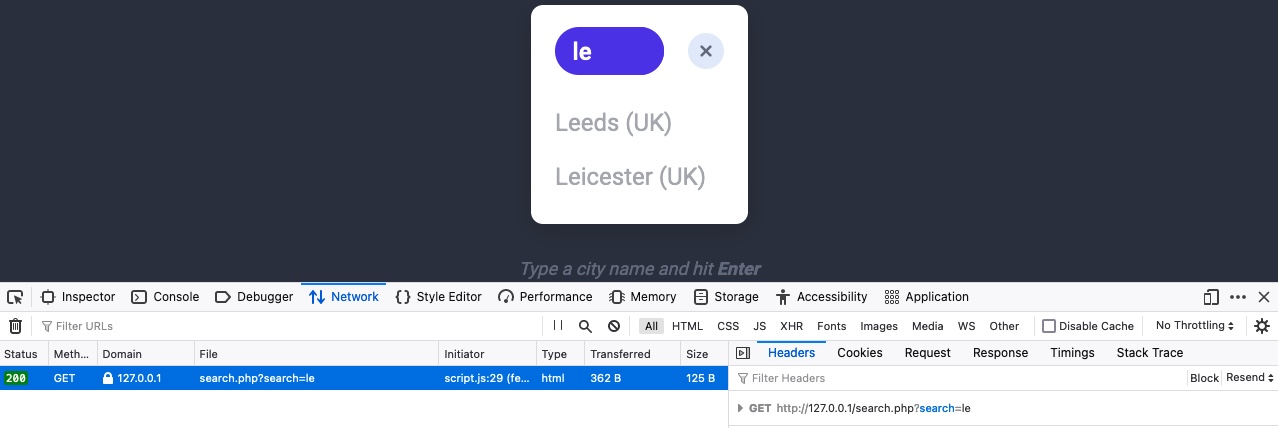
当我们点击请求时,它会被发送到search.php,并在URL中使用GET参数search=le。这有助于我们理解搜索功能请求另一个页面的结果。
现在,我们可以直接向search.php发送相同的请求以获取完整的搜索结果,尽管它可能会以特定的格式(例如JSON)返回它们,而没有上面屏幕截图中显示的HTML布局。
要使用cURL发送GET请求,我们可以使用与上面截图中相同的URL,因为GET请求将其参数放置在URL中。但是,浏览器devtools提供了一种更方便的获取cURL命令的方法。我们可以右键单击请求并选择Copy>Copy as cURL。然后,我们可以将复制的命令粘贴到终端并执行它,我们应该得到完全相同的响应:
mikannse7@htb[/htb]$ curl 'http://<SERVER_IP>:<PORT>/search.php?search=le' -H 'Authorization: Basic YWRtaW46YWRtaW4=' |
注意:复制的命令将包含HTTP请求中使用的所有标头。但是,我们可以删除其中的大部分,只保留必要的认证头,如Authorization头。
我们还可以在浏览器devtools中重复确切的请求,选择Copy>Copy as Fetch。这将使用JavaScript Fetch库复制相同的HTTP请求。然后,我们可以通过点击[CTRL+SHIFT+K]进入JavaScript控制台选项卡,粘贴我们的Fetch命令并点击enter发送请求: 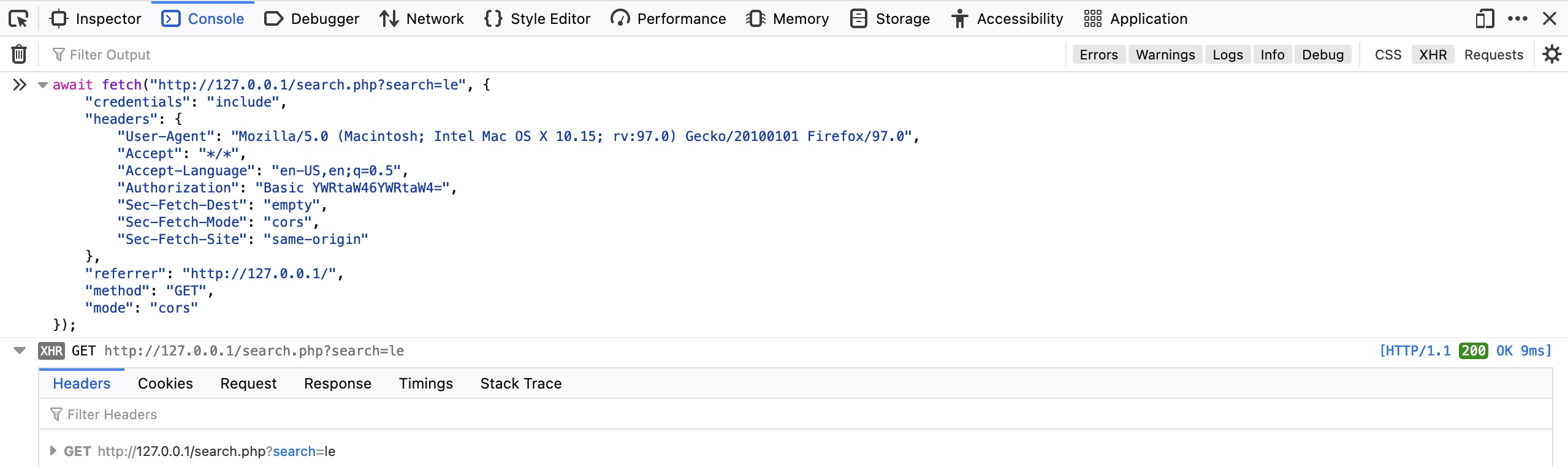
正如我们所看到的,浏览器发送了我们的请求,我们可以看到在它之后返回的响应。我们可以点击响应来查看它的详细信息,展开各种详细信息,并阅读它们。
POST
在上一节中,我们看到了Web应用程序如何使用GET请求来实现搜索和访问页面等功能。然而,每当Web应用程序需要传输文件或从URL移动用户参数时,它们都会使用POST请求。
与将用户参数放置在URL中的HTTP GET不同,HTTP POST将用户参数放置在HTTP请求主体中。这有三个主要好处:
Lack of Logging:由于POST请求可能会传输大文件(例如文件上传),因此服务器将所有上传的文件作为请求的URL的一部分进行记录是没有效率的,就像通过GET请求上传的文件一样。Less Encoding Requirements:URL被设计为共享的,这意味着它们需要符合可以转换为字母的字符。POST请求将数据放置在可以接受二进制数据的主体中。唯一需要编码的字符是那些用于分隔参数的字符。More data can be sent:最大URL长度因浏览器(Chrome/Firefox/IE)、Web服务器(IIS、Apache、nginx)、内容交付网络(Fastly、Cloudfront、Cloudflare)甚至URL缩短器(bit.ly、amzn.to)而异。一般来说,URL的长度应该保持在2,000个字符以下,因此它们不能处理大量数据。
那么,让我们来看看POST请求是如何工作的,以及我们如何利用cURL或浏览器devtools等工具来读取和发送POST请求。
Login Forms
本节末尾的练习与我们在GET部分看到的示例类似。然而,一旦我们访问Web应用程序,我们看到它使用PHP登录表单而不是HTTP基本身份验证: 
如果我们尝试使用admin:admin登录,我们会看到一个类似于我们之前在GET部分看到的搜索功能: 
如果我们清除浏览器devtools中的Network选项卡并尝试再次登录,我们将看到许多请求正在发送。我们可以通过我们的服务器IP过滤请求,所以它只会显示去往Web应用程序的Web服务器的请求(即过滤掉外部请求),我们会注意到发送了以下POST请求: 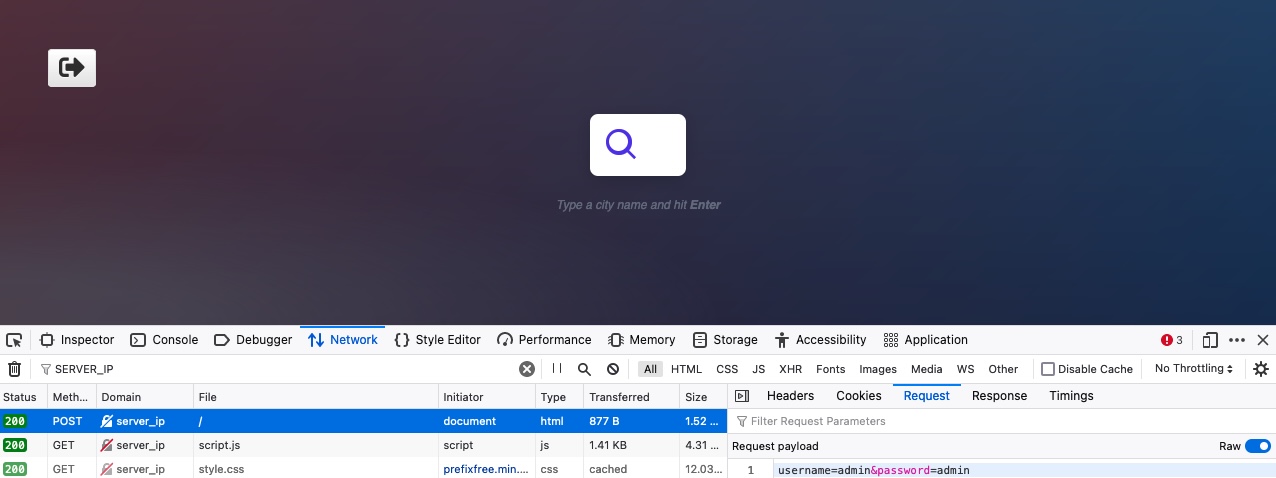
我们可以单击请求,单击Request选项卡(显示请求主体),然后单击Raw按钮以显示原始请求数据。我们看到以下数据作为POST请求数据发送:
Code:
username=admin&password=admin |
有了请求数据,我们可以尝试用cURL发送一个类似的请求,看看这是否也允许我们登录。此外,正如我们在上一节中所做的那样,我们可以简单地右键单击请求并选择Copy>Copy as cURL。但是,能够手动创建POST请求是很重要的,所以让我们尝试一下。
我们将使用-X POST标志来发送POST请求。然后,要添加POST数据,我们可以使用-d标志并在其后添加上述数据,如下所示:
mikannse7@htb[/htb]$ curl -X POST -d 'username=admin&password=admin' http://<SERVER_IP>:<PORT>/ |
如果我们检查HTML代码,我们不会看到登录表单代码,但会看到搜索功能代码,这表明我们确实得到了验证。
提示:许多登录表单在经过身份验证后会将我们重定向到不同的页面(例如/dashboard. php)。如果我们想使用cURL重定向,我们可以使用-L标志。
Authenticated Cookies
如果我们成功地通过了身份验证,我们应该已经收到了一个cookie,这样我们的浏览器就可以持久化我们的身份验证,并且我们不需要每次访问页面时都登录。我们可以使用-v或-i标志来查看响应,它应该包含带有我们身份验证cookie的Set-Cookie头:
mikannse7@htb[/htb]$ curl -X POST -d 'username=admin&password=admin' http://<SERVER_IP>:<PORT>/ -i |
有了经过身份验证的cookie,我们现在应该能够与Web应用程序交互,而无需每次都提供凭据。为了测试这一点,我们可以在cURL中使用-b标志设置上述cookie,如下所示:
mikannse7@htb[/htb]$ curl -b 'PHPSESSID=c1nsa6op7vtk7kdis7bcnbadf1' http://<SERVER_IP>:<PORT>/ |
正如我们所看到的,我们确实通过了身份验证,并进入了搜索功能。也可以将cookie指定为标头,如下所示:
Code:
curl -H 'Cookie: PHPSESSID=c1nsa6op7vtk7kdis7bcnbadf1' http://<SERVER_IP>:<PORT>/ |
我们也可以用我们的浏览器尝试同样的事情。让我们先注销,然后我们应该回到登录页面。然后,我们可以使用[Storage]转到devtools中的SHIFT+F9选项卡。在Storage选项卡中,我们可以单击左侧窗格中的Cookies并选择我们的网站以查看我们当前的Cookie。我们可能有也可能没有现有的cookie,但是如果我们注销了,那么我们的PHP cookie就不应该被认证,这就是为什么如果我们得到的是登录表单而不是搜索功能: 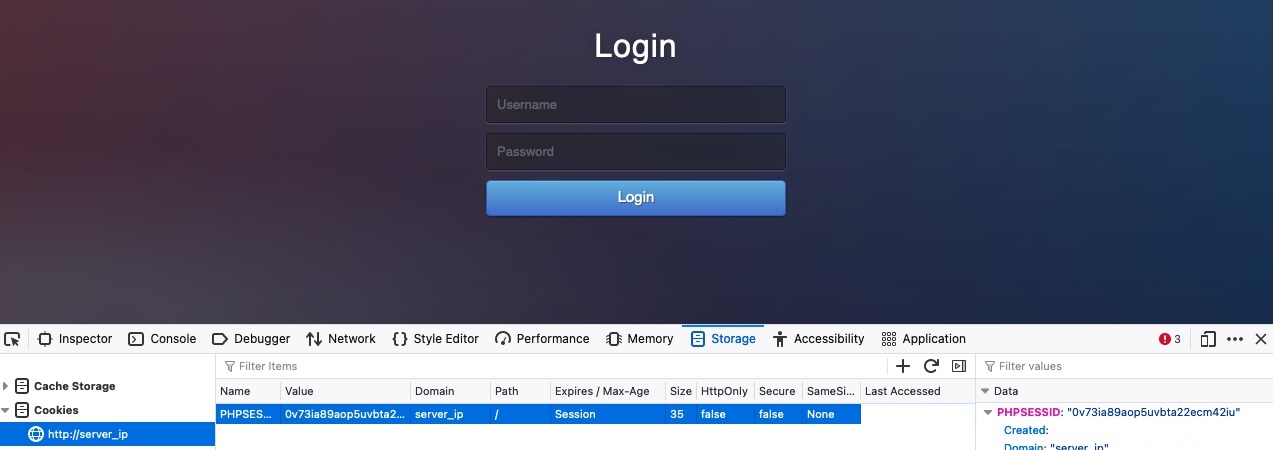
现在,让我们尝试使用前面的身份验证cookie,看看是否可以在不提供凭据的情况下进入。要做到这一点,我们可以简单地将cookie值替换为我们自己的值。否则,我们可以右键单击Cookie并选择Delete All,然后单击+图标以添加新Cookie。之后,我们需要输入cookie名称,即=(PHPSESSID)之前的部分,然后输入cookie值,即=(c1nsa6op7vtk7kdis7bcnbadf1)之后的部分。然后,一旦我们的cookie被设置,我们就可以刷新页面,我们将看到我们确实得到了认证,而不需要登录,只需使用一个经过认证的cookie: 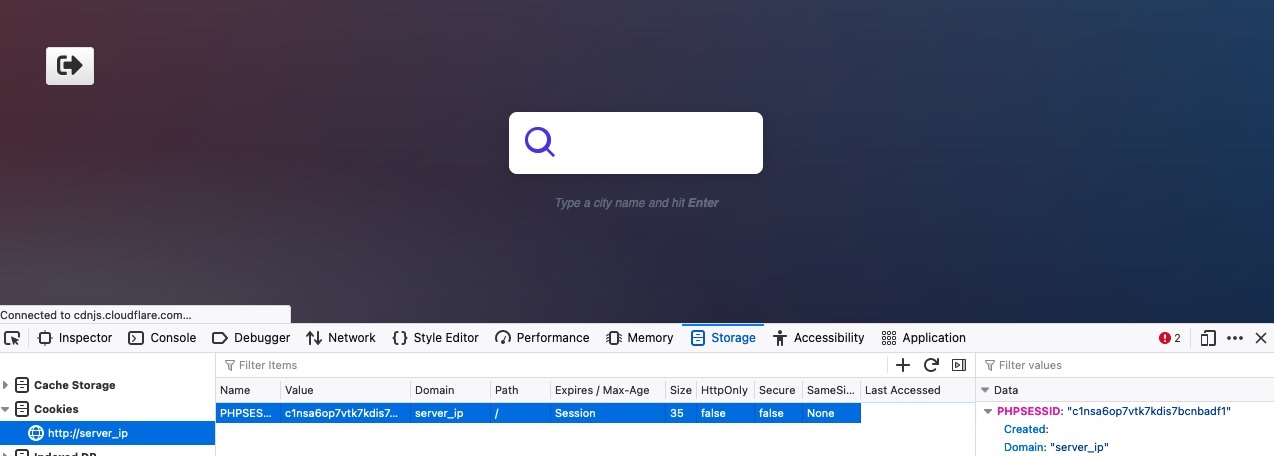
正如我们所看到的,拥有一个有效的cookie可能足以在许多Web应用程序中进行身份验证。这可能是某些Web攻击的重要组成部分,例如跨站点脚本。
JSON Data
最后,让我们看看当我们与City Search函数交互时会发送什么请求。为此,我们将转到浏览器devtools中的Network选项卡,然后单击垃圾桶图标以清除所有请求。然后,我们可以进行任何搜索查询来查看发送了哪些请求: 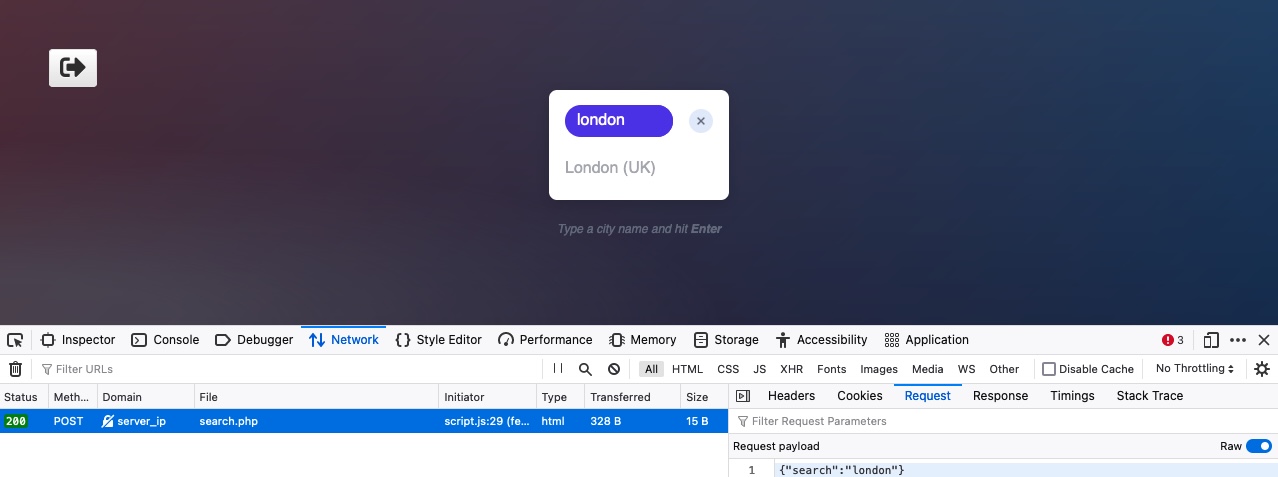
正如我们所看到的,搜索表单向search.php发送了一个POST请求,其中包含以下数据:
Code:
{"search":"london"} |
POST数据似乎是JSON格式的,所以我们的请求必须将Content-Type头指定为application/json。我们可以通过右键单击请求并选择Copy>Copy Request Headers来确认这一点:
Code:
POST /search.php HTTP/1.1 |
事实上,我们有Content-Type: application/json。让我们尝试像之前一样复制这个请求,但是同时包含cookie和content-type头,并将我们的请求发送到search.php:
mikannse7@htb[/htb]$ curl -X POST -d '{"search":"london"}' -b 'PHPSESSID=c1nsa6op7vtk7kdis7bcnbadf1' -H 'Content-Type: application/json' http://<SERVER_IP>:<PORT>/search.php |
正如我们所看到的,我们能够直接与搜索功能交互,而无需登录或与Web应用程序前端交互。在执行Web应用程序评估或错误奖励练习时,这可能是一项基本技能,因为以这种方式测试Web应用程序要快得多。
练习:尝试重复上述请求,但不添加cookie或内容类型标头,并查看Web应用程序的行为有何不同。
最后,让我们尝试使用Fetch重复上面的请求,就像我们在上一节中所做的那样。我们可以右键单击请求并选择Copy>Copy as Fetch,然后转到Console选项卡并在那里执行我们的代码: 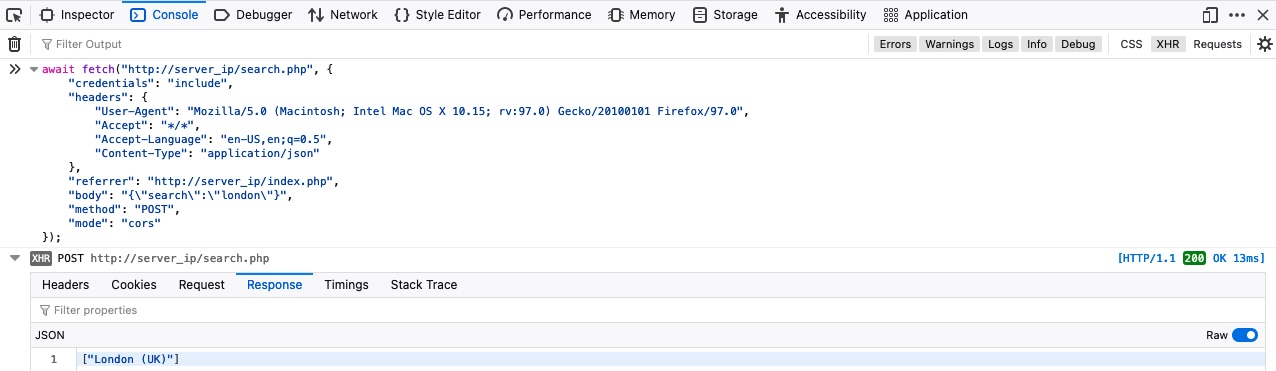
我们的请求成功地返回了与cURL相同的数据。Try to search for different cities by directly interacting with the search.php through Fetch or cURL.
CRUD API
在前面的章节中,我们看到了一个使用PHP参数搜索城市名称的City Search Web应用程序的示例。本节将介绍这样的Web应用程序如何利用API来执行相同的操作,我们将直接与API端点进行交互。
APIs
有几种类型的API。许多API用于与数据库交互,这样我们就可以在API查询中指定请求的表和请求的行,然后使用HTTP方法执行所需的操作。例如,对于我们示例中的api.php端点,如果我们想要更新数据库中的city表,并且我们将要更新的行具有城市名称london,则URL将如下所示:
Code:
curl -X PUT http://<SERVER_IP>:<PORT>/api.php/city/london ...SNIP... |
CRUD
正如我们所看到的,我们可以很容易地通过这样的API指定我们想要执行操作的表和行。然后我们可以利用不同的HTTP方法对该行执行不同的操作。一般来说,API对请求的数据库实体执行4个主要操作:
| Operation | HTTP Method | Description |
|---|---|---|
Create |
POST |
将指定的数据添加到数据库表中 |
Read |
GET |
从数据库表中读取指定的实体 |
Update |
PUT |
更新指定数据库表的数据 |
Delete |
DELETE |
从数据库表中删除指定行 |
这四个操作主要与通常所知的CRUD API相关联,但同样的原理也用于REST API和其他几种类型的API。当然,并不是所有的API都以相同的方式工作,用户访问控制将限制我们可以执行的操作以及我们可以看到的结果。Web应用程序简介模块进一步解释了这些概念,因此您可以参考它了解有关API及其用法的更多详细信息。
Read
与API交互时,我们要做的第一件事就是阅读数据。如前所述,我们可以简单地在API之后指定表名(例如/city),然后指定我们的搜索词(例如/london),如下所示:
mikannse7@htb[/htb]$ curl http://<SERVER_IP>:<PORT>/api.php/city/london |
我们看到结果以JSON字符串的形式发送。要将其正确格式化为JSON格式,我们可以将输出通过管道传输到jq实用程序,该实用程序将正确格式化它。我们还将使用-s静默任何不需要的cURL输出,如下所示:
mikannse7@htb[/htb]$ curl -s http://<SERVER_IP>:<PORT>/api.php/city/london | jq |
正如我们所看到的,我们得到了一个格式很好的输出。我们也可以提供一个搜索词,并获得所有匹配的结果:
mikannse7@htb[/htb]$ curl -s http://<SERVER_IP>:<PORT>/api.php/city/le | jq |
最后,我们可以传递一个空字符串来检索表中的所有条目:
mikannse7@htb[/htb]$ curl -s http://<SERVER_IP>:<PORT>/api.php/city/ | jq |
Create
要添加新条目,我们可以使用HTTP POST请求,这与我们在上一节中执行的操作非常相似。我们可以简单地POST我们的JSON数据,它将被添加到表中。由于此API使用JSON数据,因此我们还将Content-Type头设置为JSON,如下所示:
mikannse7@htb[/htb]$ curl -X POST http://<SERVER_IP>:<PORT>/api.php/city/ -d '{"city_name":"HTB_City", "country_name":"HTB"}' -H 'Content-Type: application/json' |
现在,我们可以读取我们添加的城市的内容(HTB_City),看看它是否成功添加:
mikannse7@htb[/htb]$ curl -s http://<SERVER_IP>:<PORT>/api.php/city/HTB_City | jq |
正如我们所看到的,一个新的城市被创造出来,这是以前不存在的。
练习:尝试通过浏览器devtools添加一个新城市,方法是使用上一节中使用的Fetch POST请求之一。
Update
现在我们知道了如何通过API读写条目,让我们开始讨论另外两个我们还没有使用过的HTTP方法:PUT和DELETE。如本节开头所述,PUT用于更新API条目并修改其详细信息,而DELETE用于删除特定实体。
注意:HTTP PATCH方法也可以用来更新API条目,而不是PUT。准确地说,PATCH用于部分更新条目(仅修改其部分数据“例如,仅城市名称”),而PUT用于更新整个条目。我们也可以使用HTTPOPTIONS方法来查看服务器接受哪一个,然后相应地使用适当的方法。在本节中,我们将重点介绍PUT方法,尽管它们的用法非常相似。
在这种情况下,使用PUT与POST非常相似,唯一的区别是我们必须在URL中指定我们想要编辑的实体的名称,否则API将不知道要编辑哪个实体。因此,我们所要做的就是在URL中指定city名称,将请求方法更改为PUT,并像POST一样提供JSON数据,如下所示:
mikannse7@htb[/htb]$ curl -X PUT http://<SERVER_IP>:<PORT>/api.php/city/london -d '{"city_name":"New_HTB_City", "country_name":"HTB"}' -H 'Content-Type: application/json' |
在上面的例子中,我们首先指定/city/london作为我们的城市,并在请求数据中传递了一个包含"city_name":"New_HTB_City"的JSON字符串。所以,伦敦城不应该再存在了,一个新的城市应该存在,名字是New_HTB_City。让我们尝试阅读两者来确认:
mikannse7@htb[/htb]$ curl -s http://<SERVER_IP>:<PORT>/api.php/city/london | jq |
mikannse7@htb[/htb]$ curl -s http://<SERVER_IP>:<PORT>/api.php/city/New_HTB_City | jq |
事实上,我们成功地用新城市取代了旧城市的名字。
注意:在某些API中,Update操作也可以用于创建新条目。基本上,我们会发送我们的数据,如果它不存在,它会创建它。例如,在上面的例子中,即使带有london城市的条目不存在,它也会创建一个新的条目,其中包含我们传递的详细信息。然而,在我们的示例中,情况并非如此。尝试更新一个不存在的城市,看看你会得到什么。
DELETE
最后,让我们尝试删除一个城市,这就像阅读一个城市一样简单。我们只需为API指定城市名称并使用HTTP DELETE方法,它就会删除条目,如下所示:
mikannse7@htb[/htb]$ curl -X DELETE http://<SERVER_IP>:<PORT>/api.php/city/New_HTB_City |
mikannse7@htb[/htb]$ curl -s http://<SERVER_IP>:<PORT>/api.php/city/New_HTB_City | jq |
正如我们所看到的,在我们删除New_HTB_City之后,当我们尝试阅读它时,我们得到一个空数组,这意味着它不再存在。
练习:尝试删除之前通过POST请求添加的任何城市,然后读取所有条目以确认它们已成功删除。
这样,我们就可以通过cURL执行所有4个CRUD操作。在一个真实的web应用程序中,这样的操作可能不允许所有用户,或者如果任何人都可以修改或删除任何条目,则会被认为是一个漏洞。每个用户都有一定的权限,他们可以read或write,其中write指的是添加,修改或删除数据。为了验证我们的用户使用API,我们需要传递一个cookie或授权头(例如JWT),就像我们在前面的部分中所做的那样。除此之外,操作与我们在本节中练习的操作类似。